个人简介
面试官好,我是湖南科技大学计算机学院准大四学生苏明月,今天面试的岗位是JAVA后端,不过PHP和前端也都能写项目,大学时成绩优良,年级200人排名16,通过四级,大一担任过班长,学习数据结构算法,打校赛,大二,加入工作室学技术,课设时写过一些小应用,学习服务系统和图书管理系统,其中图书管理系统开源到码云后得到了300多个star,大三是校学生工作室会长,我们团队是湖南科技大学企业号应用的核心开发团队,企业号关注师生人数多达8万人,我们团队开发过面对面签到、汽车入校、入党培训管理系统等应用,期间都是我在维护,任职期间工作室开发了企业号失物招领和校园闲置应用,应用使用的技术是SpringBoot、MybatisPlus和Vue,用docker部署到服务器上线后,校园闲置累积10000用户,发布闲置物品7000余件,失物招领目前有用户6000人,已经成功帮助科大学生找回了500多件物品,我们工作室也获取了校十佳科技创新团队
项目介绍:
致力于校内师生高效找回物品,校园卡、身份证、无线耳机等物品在日常经常丢失,通常的办法是发QQ空间、群聊或者其他社交平台,这样影响范围有限,效率低,因此我们充分利用我们校企业号的优势,里面拥有校内师生的所有学号姓名等信息,因此我们只需要知道物品主人的学号或者姓名就能直接通过企业号发送信息给主人,很高效,如果没有学号和姓名的就放到首页,把物品分类好便于查找。
SpringBoot、Vue、MybatisPlus、人人开源框架、Redis、SpringCache
微信企业号登录、消息推送
阿里云图片存储
防重复提交令牌
百度的图像和文字审核
JSR303和自定义校验
定时任务,每一个小时检查有没有没审核的,推送给值班的人
难点:发布、图片、企业微信登录
最难的是需求分析和设计原型图,将应用从0到1,要知道他准确的功能
物品发布业务逻辑较为复杂,发布物品分为有个人信息和无个人信息的,后台可以控制是否人工审核
- 人工审核
- 审核通过后直接根据学号或者姓名查数据库中的用户,如果查到了就能直接微信推送
- 如果没查到就把企业号中所有的部门中的人查找一遍,因为有8万多人,并将这些人放入缓存中,一定时间内可以快速查找
- 机器审核
- 流程基本一样,在前面的基础上添 加图像和文字审核
- 如果是学号和姓名都一样就能直接推送,有一个不一样就要退到人工审核
- 人工审核
图像存储,使用的是阿里云的对象存储,降低我们的网络带宽要求
- 好玩的事情:校园闲置上线一个小时多直接用了80G流量,1G就是1元,账号直接欠费了,不能上传加载图片,后面对图片进行了前端压缩和阿里云链接携带参数进行压缩,还用了CDN流量分发,降低费用
- 图片上传是客户端直接上传,用户有可能上传图片,但是不提交表单,或者被直接调用我们的API,造成资源浪费,解决方案:
- 将上传次数存入Redis,每天限制图片上传接口的次数,超过就不能调用了,治标不治本
- 将图片上传到阿里云的临时文件夹,只有提交后才将图片移动到正确的文件夹,设置定时任务,每天凌晨定时清理临时文件夹
- 格外记录图片信息进入数据库,默认状态为未提交,只有提交后才状态变为已提交,每天凌晨定时查数据库清理未提交的图片
企业微信登录
- 前后端分离,前端需要访问微信登录地址,微信回调到自己提供的回调地址,会携带有code参数,将code参数传递给后端,后端用code登录获取用户信息即可
- 回调地址必须是域名,自己内网穿透不行,大家测试要能一起使用,测试怎么办?使用放在公网的中间静态页面,码云page,携带本地网址参数访问码云page,码云page调转到微信登录地址,让微信携带code回调到码云page上,码云page将code参数跳转到到localhost即可
项目提升:
- 文档
- 团队管理、团队协作
- 编码水平
- 项目经验、明白流程
工作室内的职责:
内部管理:
工作室规划和总结
工作室清洁值班
考勤统计
资产管理(金额、工位、显示器、电脑)
管理层召开会议
文化建设:
- 组织团建
项目建设:
- 新项目:头脑风暴、可行性分析、需求分析、原型图设计、高保真图、数据库设计、编码、测试、调整、上线、宣传
- 旧项目维护:党校培训管理系统、汽车入校、面对面签到
梯队建设:
- 招新、研发组运营组升级考核
- 技术沙龙
优点:有责任心、乐观积极、幽默、乐于助人、谦虚、有一定组织能力、为他人着想、善于合作
缺点:不够自信
自我介绍,意向,成绩,java/php,课设,任职、工作室项目,省级讲话经历,项目
Spring
简介
Spring框架:轻量级,提供IOC和AOP,提高开发人员的开发效率和可维护性
包含模块:核心容器、数据访问/集成,、Web、AOP(面向切面编程)、工具、消息和测试模块
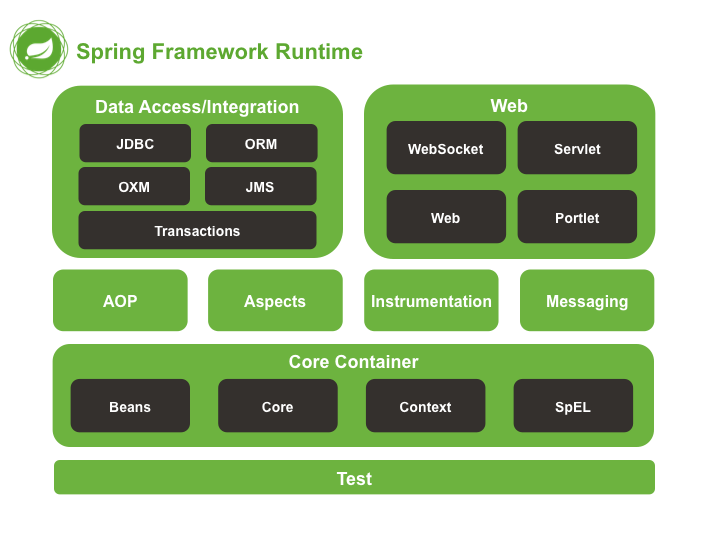
spring core:所有的基础,提供IOC依赖注入
spring aop: 切面
spring test:Junit测试支持
spring jdbc:数据库连接
IOC & AOP
IOC:依赖注入,将程序手动创建对象的控制权交给Spring框架来管理,实际上是一个MAP,里面存放各种对象
AOP:基于动态代理实现,将与业务无关的,但是又需要的逻辑(如日志、权限控制)进行封装,减少系统重复代码,降低模块间的耦合度,增强可扩展性和可维护性。
IOC初始化:
编写XML,读取成Resource,解析到BeanDefinition,注册到BeanFactory
读取:
// 加载1 通过file class
ApplicationContext context = new ClassPathXmlApplicationContext("classpath:application.xml");
// 加载2 通过file path
String path = this.getClass().getClassLoader().getResource(“”).getPath();
String filePath = path + "/.xml";
new FileSystemXmlApplicationContext(filePath);
// 加载3 通过注解
// 创建
context.getBean(MessageService.class);AOP
要代理的对象实现了某个接口,则使用JDK Proxy,没实现就要使用Cglib生成的被代理对象作为代理
Spring Aop 与AspectJ AOP的区别
Spring Aop运行时增强,基于代理
AspectJ编译时增强,基于字节码操作(编译出来的Class文件,字节码就已经织入)
AspectJ比Spring Aop功能更强大,但是Spring Aop更简单
切面较多时,使用AspectJ更快
Bean
作用域
Spring中bean的作用域
singleton,唯一的,可能会有线程安全的问题
- 在创建起容器时就同时自动创建了一个 bean 的对象,不管你是否使用,他都存在了,每次获取到的对象都是同一个对象。注意,Singleton 作用域是 Spring 中的缺省作用域
prototype:每次请求都创建(将其注入到另一个bean中,或者以程序的方式调用容器的getBean()方法),不存在线程安全的问题
- 在创建容器的时候并没有实例化,而是当我们获取bean的时候才会去创建一个对象,而且每次获取不同的对象。
request:每次http请求都创建,在request有效
session:每次session产生一个bean
global-session(spring5无了): 全局session作用域
单例模式,代理模式,工厂模式
创建
<bean id="xxxx" class="xxxx.xxxx"/>使用@Component,@Service,@Controller,@Repository注解
@Bean
@Import(User.class)
public class MicroblogUserWebApplication {
public static void main(String args[]) {
SpringApplication.run(MicroblogUserWebApplication.class, args);
}
}SpringMVC
请求流程
基于请求驱动的Web框架,根据请求映射规则分发给页面控制器处理。

请求进入根Servlet,将请求封装为HttpRequest,进入DispatherServlet,进行HandlerMapping请求映射,返回执行链,逐个执行HandlerInterceptor,来到Handler,处理业务,返回ModelAndView封装数据和视图给DispatcherServlet,让视图解析器找到对应的View实现类进行渲染数据,返回结果。

Spring MVC的处理流程是怎样的?:https://juejin.cn/post/6951343274946723870
Springboot
自动装配
简单说一下
通过引入starter,通过少量的注解和配置就能使用
实现
1.通过@SpringbootApplication里的@EnableAutoConfiguration,借助AutoConfigurationImportSelector,在selectImports中将所有符合条件的@configuration配置创建类加载到IOC容器
2.其中selectImports中getAutoConfigurationEntity中判断自动装配开关是否打开,获取@EnableAutoConfiguration注解中的exclude和excludeName,通过读取所有META-INF/spring.factories获取所有需要自动装配的所有配置类,最后跟根据ConditionalOnXXX将满足条件的加入容器
条件注解:

https://www.cnblogs.com/javaguide/p/springboot-auto-config.html
实际上Spring Framwork已经实现了的,SpringBoot只是在其基础上通过SPI的方式,进一步优化
SpringBoot定义了一套接口规范,启动时会扫描应用的Jar包中的META-INF/spring.factories文件,将文件中的配置类型信息加载到Spring容器,并执行类中定义的各种操作
Spi
https://www.jianshu.com/p/3a3edbcd8f24
服务发现机制,通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类,例如JDBC
SpringBootApplication
@SpringBootApplication看做是@Configuration、@EnableAutoConfiguration、@ComponentScan注解的集合
@EnableAutoConfiguration: 启动SpringBoot的自动配置机制
@Configuration:允许上下文中注册额外的bean或者导入其他配置类
@ComponentScan: 扫描被@Component、@Service、@Controller注解的Bean,注解默认会扫描启动类所在包下的所有的类,可以自定义不扫描某些Bean,如TypeExcludeFilter和AutoConfigurationExcludeFilter
EnableAutoConfiguration
实现是由AutoConfigurationImportSelector
AutoConfigurationImportSelector
加载自动装配类,类实现了 ImportSelector接口,也就实现了这个接口中的 selectImports方法
该方法主要用于获取所有符合条件的类的全限定类名,这些类需要被加载到 IoC 容器中,其中有getAutoConfigurationEntry方法负责加载自动配置类
getAutoConfigurationEntry
负责加载自动配置类
- 判断自动装配开关是否打开。默认spring.boot.enableautoconfiguration=true,可在 application.properties 或 application.yml 中设置
- 用于获取EnableAutoConfiguration注解中的 exclude 和 excludeName
- getCandidateConfigurations获取需要自动装配的所有配置类,loadFactoryNames读取所有SpringBootStarter下的 META-INF/spring.factories
- filter中进行筛选,@ConditionalOnXXX 中的所有条件都满足,该类才会生效。
Spring Boot自动装配的原理其实背后的主要原理就是条件注解。
当我们使用@EnableAutoConfiguration注解激活自动装配时,实质对应着很多XXXAutoConfiguration类在执行装配工作
这些XXXAutoConfiguration类是在jar中的META-INF/spring.factories文件中配置好的
@EnableAutoConfiguration通过SpringFactoriesLoader机制创建XXXAutoConfiguration这些bean
XXXAutoConfiguration的bean会依次执行并判断是否需要创建对应的bean注入到Spring容器中。
在每个XXXAutoConfiguration类中,都会利用多种类型的条件注解@ConditionOnXXX对当前的应用环境做判断,如应用程序是否为Web应用、classpath路径上是否包含对应的类、Spring容器中是否已经包含了对应类型的bean。如果判断条件都成立,XXXAutoConfiguration就会认为需要向Spring容器中注入这个bean,否则就忽略。
实现自定义线程池Starter
1.创建工程
2.引入spring-boot-starter依赖
3.创建ThreadPoolAutoConfiguration
@Configuration
public class ThreadPoolAutoConfiguration {
@Bean
@ConditionalOnClass(ThreadPoolExecutor.class) // 需要有这个类才会生效
public ThreadPoolExecutor MyThreadPool() {
return ThreadPoolExecutor(
10, 10, 10, ThimeUnit.SECONDS, new ArrayBlockingQueue(100);
)
}
}4.resources包下创建 META-INF/spring.factories
5.引入starters
Spring Boot 通过@EnableAutoConfiguration开启自动装配,通过 SpringFactoriesLoader 最终加载META-INF/spring.factories中的自动配置类实现自动装配,自动配置类其实就是通过@Conditional按需加载的配置类,想要其生效必须引入spring-boot-starter-xxx包实现起步依赖
专有注解
@Configuration
@AutoConfigureAfter // 完成某个bean后实例化这个bean
@ConditionOn[Miss]Bean
@ConditionOnClass
SpingBootApplication
@EnableAutoConfiguration
@ComponentScan初始化完执行操作
构造方法 –> @PostConstruct –> InitializingBean接口 –> @Bean 注入的init-method
// 1
@PostConstruct
public void init() {
}
// 2 initializingBean
public TestInit implements InitializingBean {
@Override
public void afterPropertiesSet() throws Exception {
}
}
// 3 其值为要执行的方法 InitTest.initMethod()
@Bean(initMethod = "initMethod")
public InitTest initTest() {
return new InitTest();
}面试问题
事务
@Transactional(rollbackFor = {RuntimeException.class, Error.class} , isolation=Isolation.DEFAULT)默认default,与数据库隔离级别一致,读未提交,读已提交,可重复读,串行化
其设计模式
工厂设计模式、观察者模式、单例模式、模板模式、代理模式
工厂设计模式
BeanFactory 或 ApplicationContext 创建bean
beanFactory:延迟注入,需要才注入,占用内存少,程序启动快
ApplicationContext:容器启动就创建,ApplicationContext扩展了BeanFactory,用的更多
- ClassPathXmlApplication: 上下文文件当做类路径资源
- FileSystemApplication:文件系统的XML文件载入上下文信息
- XmlWebApplicationContext:web系统中的xml文件载入上下文信息
常见注解
@Async
简单使用
// 有返回值
@Async
public Future<String> asyncMethod3() throws InterruptedException {
System.out.println("Spring1自带的线程池" + Thread.currentThread().getName() + "-" + sdf.format(new Date()));
return new AsyncResult<>("异步方法3执行完成!");
}
// 获取
public String test4()throws Exception{
Future<String> future = asyncService.asyncMethod3();
// future.get() 阻塞
String s = "";
while (true){//这里使用了循环判断,等待获取结果信息
if (future.isDone()){//判断是否执行完毕
s = future.get();
break;
}
System.out.println("Continue doing something else...");
Thread.sleep(1000);
}
return s;
}https://blog.csdn.net/ignorewho/article/details/85603920
SimpleAsyncTaskExecutor
- 默认使用SimpleAsyncTaskExecutor
- 最大无限线程,每次执行任务都会启动新的线程
- 能够通过concurrencyLimit控制并发数量,默认-1不控制
- 获取monitor锁
- 如果超过数量,进行monitor.wait,释放该锁,进入该对象等待锁池,等待该对象的notify
- 合适的并发数量才能继续
- 线程run完后monitor.notify释放
- 获取monitor锁
使用SimpleAsyncTaskExecutor
https://www.cnblogs.com/kaleidoscope/p/9675104.html
线程执行器
| SimpleAsyncTaskExecutor | 每次请求新开线程,没有最大线程数设置.不是真的线程池,这个类不重用线程,每次调用都会创建一个新的线程。 –【1】 |
|---|---|
| SyncTaskExecutor | 不是异步的线程.同步可以用SyncTaskExecutor,但这个可以说不算一个线程池,因为还在原线程执行。这个类没有实现异步调用,只是一个同步操作。 |
| ConcurrentTaskExecutor | Executor的适配类,不推荐使用。如果ThreadPoolTaskExecutor不满足要求时,才用考虑使用这个类。 |
| SimpleThreadPoolTaskExecutor | 监听Spring’s lifecycle callbacks,并且可以和Quartz的Component兼容.是Quartz的SimpleThreadPool的类。线程池同时被quartz和非quartz使用,才需要使用此类。 |
| ThreadPoolTaskExecutor | 最常用。要求jdk版本大于等于5。可以在程序而不是xml里修改线程池的配置.其实质是对java.util.concurrent.ThreadPoolExecutor的包装。 |
| TimerTaskExecutor | |
| WorkManagerTaskExecutor |
自定义线程池
关于@Async的默认调用规则,会优先查询源码中实现AsyncConfigurer这个接口的类(AsyncConfigurerSupport)。
AsyncConfigurerSupport默认配置的线程池和异步处理方法均为空
继承AsyncConfigurerSupport或者重新实现AsyncConfigurer接口,重新实现 public Executor getAsyncExecutor()方法,指定线程池。
重新实现接口AsyncConfigurer
继承AsyncConfigurerSupport
配置由自定义的TaskExecutor替代内置的任务执行器
接口AsyncConfigurer
@Configuration
public class AsyncConfiguration implements AsyncConfigurer {
int corePoolSize = 10;
int maxPoolSize = 50;
int queueCapacity = 10;
String threadNamePrefix = "kingDeeAsyncExecutor-";
int awaitTerminationSeconds = 5;
@Bean("kingAsyncExecutor")
public ThreadPoolTaskExecutor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.setThreadNamePrefix(threadNamePrefix);
// 设置线程池关闭的时候等待所有任务都完成再继续销毁其他的Bean
executor.setWaitForTasksToCompleteOnShutdown(true);
// 使用自定义的跨线程的请求级别线程工厂类
executor.setAwaitTerminationSeconds(awaitTerminationSeconds);
// 初始化队列和执行器
executor.initialize();
return executor;
}
@Override
public Executor getAsyncExecutor() {
return executor();
}
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return (ex, method, params) -> ErrorLogger.getInstance().log(String.format("执行异步任务'%s'", method), ex);
}
}继承AsyncConfigurerSupport
@Configuration
@EnableAsync
class SpringAsyncConfigurer extends AsyncConfigurerSupport {
// 同上
}原理
https://juejin.cn/post/7008368482224078856
初始化解析@Async注解的切面类


@EnableAsync,@Import
AsyncConfigurationSelector
决定使用JDK还是ASPECTJ代理模式
ProxyAsyncConfiguration
- 继承AbstractAsyncConfiguration,其中setConfigurers注入集合AsyncConfigurer
- 新建AsyncAnnotationBeanPostProcessor后置处理器并进行参数初始化
AsyncAnnotationBeanPostProcessor
- setBeanFactory初始化AsyncAnnotationAdvisor切面
AsyncAnnotationAdvisor
将@Async注解存入切面
具体处理在AbstractAdvisingBeanPostProcessor.postProcessAfterInitialization方法
AsyncExecutionInterceptor
invoke
doSubmit
疑问
- 公司的为什么使用simpleAsyncTaskExecutor,而代码分析是使用applicationTaskExecutor,@ConditionalOnMissingBean({Executor.class})
- 循环依赖的三级缓存,TODO
公司
jres中设置monitorTaskExecutor,默认50个核心线程,存活时间0(用完就消灭),给框架启动使用
但是@Async使用的还是simpleAsyncTaskExecutor
设计模式
单例模式
线程池、缓存、日志对象、注册表等
好处:
频繁使用,忽略创建对象的时间,减少系统消耗
new减少,系统内存使用频率降低,减少GC压力
代理
与业务无关,通用的逻辑,事务处理、日志管理、权限控制封装起来,减少重复代码、降低耦合
jdk proxy:要类实现接口,速度更快
cglib:类不用实现接口,灵活
模板方法
父类的方法定义执行顺序,子类具体实现每个步骤的方法
public abstract class Template {
//这是我们的模板方法
public final void TemplateMethod(){
PrimitiveOperation1();
PrimitiveOperation2();
PrimitiveOperation3();
}
protected void PrimitiveOperation1(){
//当前类实现
}
//被子类实现的方法
protected abstract void PrimitiveOperation2();
protected abstract void PrimitiveOperation3();
}观察者模式
当一个对象发生改变,所依赖的对象作出反应,比如添加商品需要重新更新商品索引
事件角色: 启动、停止、刷新、关闭
ContextStartedEvent:ApplicationContext启动后触发的事件;ContextStoppedEvent:ApplicationContext停止后触发的事件;ContextRefreshedEvent:ApplicationContext初始化或刷新完成后触发的事件;ContextClosedEvent:ApplicationContext关闭后触发的事件。
监听者角色:
ApplicationListener 充当了事件监听者角色,它是一个接口,里面只定义了一个 onApplicationEvent()方法来处理ApplicationEvent
发布者角色:
ApplicationEventPublisher 接口的publishEvent()这个方法在AbstractApplicationContext类中被实现,阅读这个方法的实现,你会发现实际上事件真正是通过ApplicationEventMulticaster来广播出去的
步骤:
- 定义一个事件: 实现一个继承自
ApplicationEvent,并且写相应的构造函数; - 定义一个事件监听者:实现
ApplicationListener接口,重写onApplicationEvent()方法; - 使用事件发布者发布消息: 可以通过
ApplicationEventPublisher的publishEvent()方法发布消息。
// 定义一个事件,继承自ApplicationEvent并且写相应的构造函数
public class DemoEvent extends ApplicationEvent{
private static final long serialVersionUID = 1L;
private String message;
public DemoEvent(Object source,String message){
super(source);
this.message = message;
}
public String getMessage() {
return message;
}
}
// 定义一个事件监听者,实现ApplicationListener接口,重写 onApplicationEvent() 方法;
@Component
public class DemoListener implements ApplicationListener<DemoEvent>{
//使用onApplicationEvent接收消息
@Override
public void onApplicationEvent(DemoEvent event) {
String msg = event.getMessage();
System.out.println("接收到的信息是:"+msg);
}
}
// 发布事件,可以通过ApplicationEventPublisher 的 publishEvent() 方法发布消息。
@Component
public class DemoPublisher {
@Autowired
ApplicationContext applicationContext;
public void publish(String message){
//发布事件
applicationContext.publishEvent(
new DemoEvent(this, message)
);
}
}Zookeeper
开源的分布式协调服务
ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
特点:
- 将数据保存在内存中
- 顺序一致性: 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
- 原子性: 要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
- 单一系统映像 : 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
- 可靠性: 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
Dubbo
简介
两个不同服务器上的服务要通过网络编程才实现,RPC让调用远程方法像调用本地方法一样简单
网站规模增大,单一、垂直架构无法满足需求,分布式架构下远程调用关系复杂,需要负载均衡和服务监控
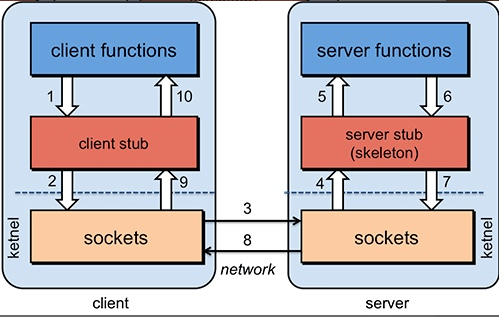
客户端以本地方法调用远程服务
客户端 stub接受到调用后将方法、参数序列化,找到远程服务地址,发送信息
服务端stub接受到消息反序列化为Java对象,根据RPCRequest中的类、方法、方法参数等信息调用本地方法
服务端将结果序列化RpcResponse交给消费方
客户端stub接受消息反序列化为java对象
核心:
- 面向接口代理、高性能RPC调用
- 智能容错和负载均衡
- 服务自动注册和发现
- 高度可扩展
- 运行期流量调度
- 可视化服务治理和运维
架构
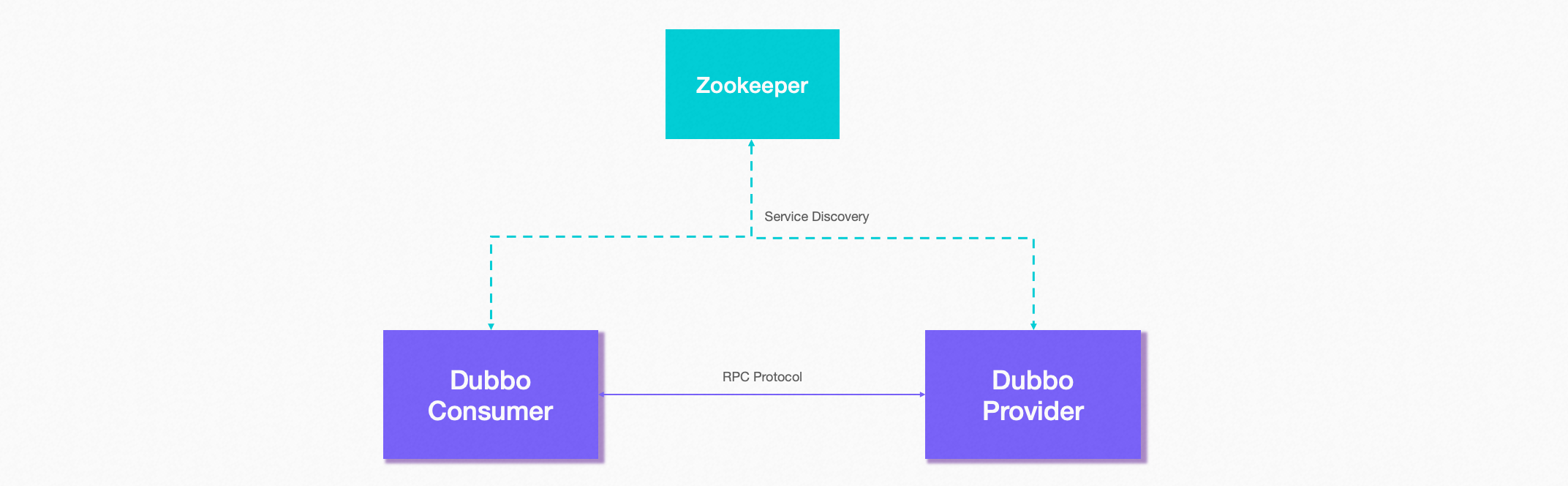
提供方注册到注册中心,消费者订阅服务,从注册中心获取到提供者的地址,通过负载均衡选择一个提供方直接调用
提供方数据变更,注册中心会发送给消费者
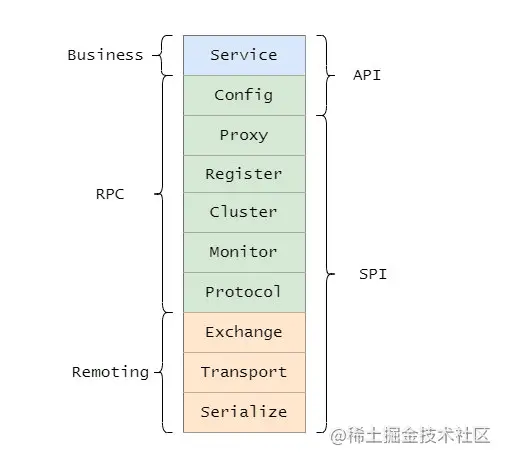
Service,业务层
Config,配置层,主要围绕 ServiceConfig 和 ReferenceConfig,初始化配置信息。
Proxy,代理层,服务提供者还是消费者都会生成一个代理类,使得服务接口透明化,代理层做远程调用和返回结果。
Register,注册层,封装了服务注册和发现。
Cluster,路由和集群容错层,负责选取具体调用的节点,处理特殊的调用要求和负责远程调用失败的容错措施。
Monitor,监控层,负责监控统计调用时间和次数。
Portocol,远程调用层,主要是封装 RPC 调用,主要负责管理 Invoker,Invoker代表一个抽象封装了的执行体,之后再做详解。
Exchange,信息交换层,用来封装请求响应模型,同步转异步。
Transport,网络传输层,抽象了网络传输的统一接口,这样用户想用 Netty 就用 Netty,想用 Mina 就用 Mina。
Serialize,序列化层,将数据序列化成二进制流,当然也做反序列化。
。
设计RPC框架
https://juejin.cn/post/6870276943448080392
公用jar包维护接口,代理类实现对远程调用,调用需要注册中心获取地址,负载均衡调用,调用要有容错机制,网络传输,规定序列化格式,
服务提供方实现接口,暴露给注册中心地址,使用约定的协议来处理请求,进行反序列化,再将请求放入线程池进行处理,将结果返回
这么多远程接口调用,需要监控运维
SpringCloud
https://blog.csdn.net/ThinkWon/article/details/104397367
简介
为什么用
Spring Cloud好处
spring大家族,保证稳定更新、完善
组件丰富、功能齐全,为微服务提供完整支持,配置管理、服务发现、断路器、微服务网关
活跃度高、问题能找到方案
服务拆分力度细,有利于资源重复利用
缺点
微服务治理成本高,不利于维护,分布式开发挑战大
与Springboot的区别
springboot专注快速开发个体微服务,springcloud关注全局的微服务协调治理,依赖于springboot
分布式概念
微服务、服务发现、注册中心、配置中心、远程调用、网关、熔断器
MyBatis
https://blog.csdn.net/ThinkWon/article/details/101292950
简介
MyBatis是持久层框架,半ORM(关系映射框架)
支持定制化SQL,避免所有JDBC代码和手动设置参数获取结果集
使用简单的XML或注解来配置和映射原生类型、接口和JAVA的POJO为数据库中的记录
JDBC开发问题与解决
连接池、参数与结果集存在硬编码、结果集需要重复处理
- 频繁创建数据库连接对象、释放,资源浪费,影响性能,可以通过连接池解决,但是需要自己实现
- mybatis-config.xml中配置数据库连接池,使用连接池管理连接
- SQL语句定义、参数设置、结果集处理存在硬编码,SQL可能变化,需要修改JAVA代码,不好维护
- XXXMapper.xml文件中与java代码分离
- PreparedStatment占位符存在硬编码,修改sql还要修改代码,不易维护
- Mybatis自动将java对象映射到sql语句
- 结果集处理存在重复代码,处理麻烦
- 自动将sql映射到java对象
Mybatis缺点
- SQL多,尤其字段多、关联表时
- SQL语句依赖数据库,移植性差
与Hibernate
相同点:
都是对JDBC的封装,都是持久层框架,都用于dao层开发
不同点:
映射关系:
- Mybatis是半自动映射框架,配置java对象与sql语句结果对应,多表关联关系配置简单
- Hibernate是全表映射的框架,相对复杂
SQL优化和移植性:
- Hibernate对SQL语句封装提供日志、缓存、级联等特性,有HQL,数据库无关性比较好,消耗性能,代码少,SQL优化困难
- MyBatis需要手动编写SQL,支持动态SQL,开发工作量大,直接使用SQL语句操作数据库,优化简单,不支持数据库无关性
开发和学习成本
- Hibernate重量级框架,门槛高,中小型项目
- MyBatis轻量级,门槛低,适合大型项目
运行
预编译
SQL预编译是指数据库驱动在发送SQL语句和参数给DBMS之前对SQL语句进行编译
JDBC使用PreparedStatment来抽象编译语句,使用预编译可以优化SQL执行,预编译后的SQL多数情况下可以直接执行,DBMS不需要再次编译,越复杂的SQL编译难度越大,预编译阶段可以合并多次操作为一个操作
预编译对象可以重复使用,把preparedStatement对象缓存下来,下次对于同一个SQL,可以直接使用
#{}和${}
#{}
#{}是占位符,预编译处理,防止SQL注入,提高安全性
#{}传入参数是以字符串传入,SQL中的#{}替换为?号,调用PreparedStatment的set方法来赋值
#{}对应变量替换发生在DBMS中,自动加上单引号
${}
${}是连接符,只是字符串替换,不进行预编译处理
${}变量替换是在DBMS外
Dao和XMl如何关联
mapperLocations和mapperPackage标识了各个xml对应的位置
xml中有namespace对应着mapper接口的位置
加载xml
- 初始化SqlSessionFactoryBean时,找到mapperLocations路径解析所有mapper文件
- 根据mapper中的每句SQL标签生成对应的SqlSource,动态DynamicSqlSource:SqlNode(IfSqlNode、WhereSqlNode等),静态staticSqlSource:String
- xml文件中每一个SQL标签对应一个MappedStatement对象( id(namespace +方法id)和sqlSource )
- 解析完后,BaseBuilder中configuration对象具有所有sql信息
configuration ——> MappedStatements(全限定类名和方法名) ——> SqlSource (sqlNode,String)
关联
mapperScannerConfigurer实现了BeanDefinitionRegistryPostProcessor
方法postProcessBeanDefinitionRegistry中的ClassPathmapperScanner使用了父类的scan方法,父类的scan使用到子类的doScan
扫描了所有Mapper接口,注册为BeanDefinition对象并返回,对processBeanDefinitions设置了属性
- 包括beanClass为MapperFactoryBean,说明mapper接口在Spring容器中,beanName是我们的全类名userMapper,实例化对象为MapperFactoryBean
- 设置了sqlSessionFactory,在为BeanDefinition对象设置PropertyValue的时候,会调用到setSqlSessionFactory()
在setSqlSessionFactory中,sqlSession获取SqlSessionTemplate实例,其中主要包含sqlSessionFactory和sqlSessionProxy,sqlSessionProxy是SqlSession接口的代理对象,实际调用invoke方法
注入属性时,返回的是代理类,执行dao方法时,调用代理类的invoke方法
常用
like
-- 1. #{}解析变量自动加上'',所以要用""
"%"#{param}"%"
-- 2.concat
concat('%', #{param}, '%')
-- 3.使用bind标签
<bind name="param" value=" '%' +param + '%' ">多参数
// 1. String name, int id -> #{0}, #{1}
// 2. @Param("name") String name, @Param("id") int id
// 3. Map #{name} #{id}
// 4.javaBean paramterType批量插入
foreach
<!--
int addEmpsBatch(@Param("emps") List<Employee> emps);
item/index/open/separator/close
-->
<insert id="addEmpsBatch">
INSERT INTO emp(ename,gender,email,did)
VALUES
<foreach collection="emps" item="emp" separator=",">
(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>获取自增的主键
<insert id="insertUser" useGeneratedKeys="true" keyProperty="userId" >
insert into user(
user_name, user_password, create_time)
values( #{userName}, #{userPassword} , #{createTime, jdbcType= TIMESTAMP} )
</insert>字段名不一样
resultMap="myResultMap"
一对一、一对多
通过resultMap中的
association节点配置多对一
collection配置一对多即可
嵌套查询是先查一个表,根据结果的外键id,去另一个表查询数据,通过assocation和collection问题
mapper接口调用要求
- id与接口名相同
- 接口输入与sql的parameterType类型相同
- 接口输出与resultType类型相同
- namespace即为接口类路径
XML中常见标签
select insert update delete
resultMap(和result) paramterMap
sql include selectKey
where if
choose when otherwise
foreach trim set bind
分页
插件中拦截sql,添加物理分页语句和参数
缓存
一级缓存:HashMap本地缓存,作用域为session,session结束后其中的cache就清空
二级缓存:HashMap缓存,作用域为Mapper(NameSpace),默认不打开
更新机制:某一作用域下进行增删改操作后,select缓存清空
操作系统
基础
是什么
- 本质是软件程序,管理计算机硬件和软件资源(CPU、内存、设备)
- 屏蔽硬件复杂性
- 操作系统内核负责系统的内存管理、硬件设备管理、文件系统管理、应用程序的管理,连接应用和硬件
系统调用
用户态:用户态运行的进程可以读取用户程序的数据
系统态:系统态的进程可以访问计算机任何资源
用户态的应用程序调用系统态的功能需要系统调用(进程控制、内存管理、文件管理、设备管理)
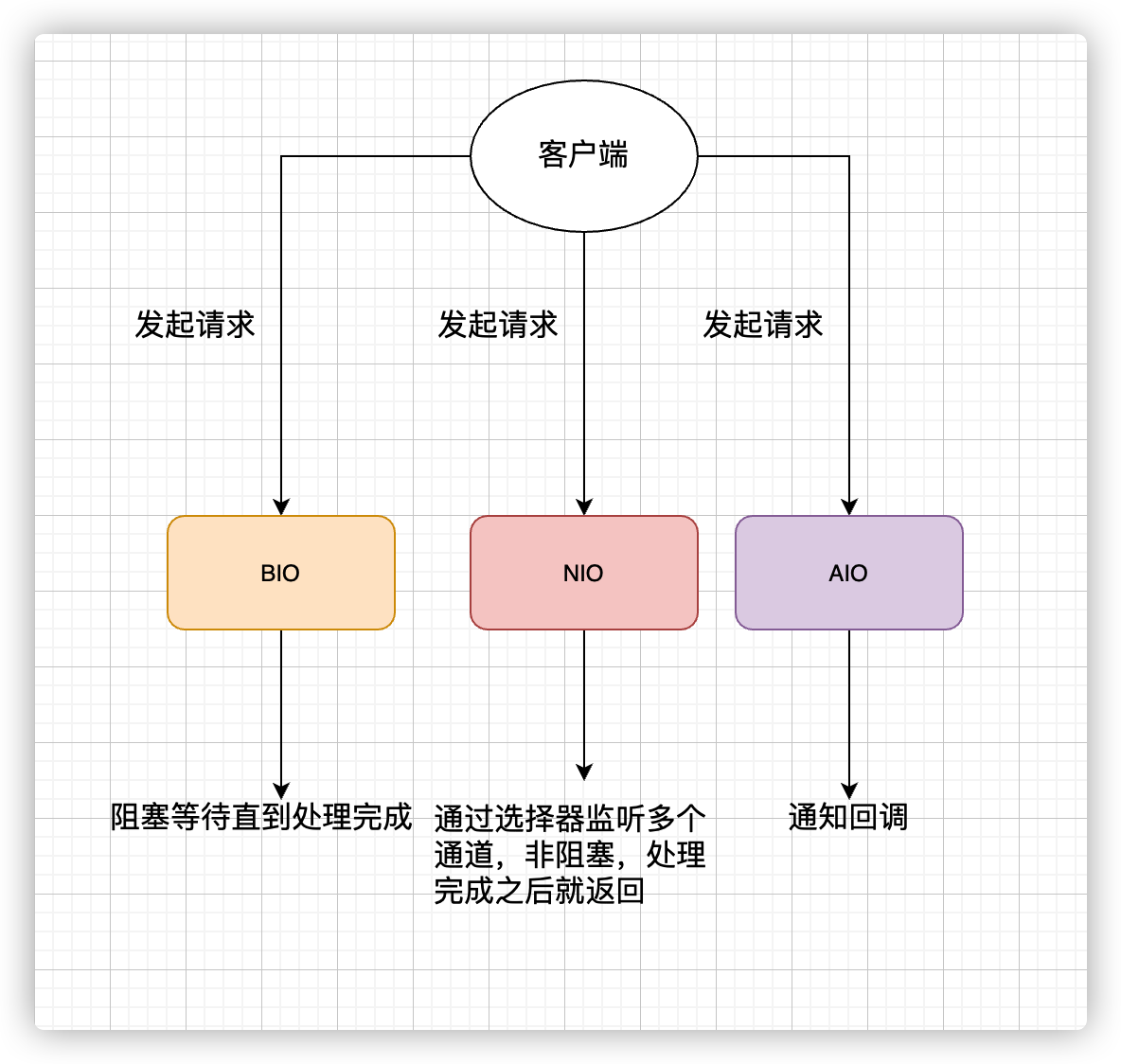
IO
总结:
因为系统分为用户空间和内核空间,对系统文件等操作,用户程序没有权限,只能发起系统调用,让系统准备好IO设备准备好数据,并将数据从内核空间拷贝到用户空间
IO模型在unix分为同步阻塞、同步非阻塞、IO多路复用、信号驱动IO、异步IO
JAVA模型
BIO:一直阻塞,直到处理完成
NIO
同步非阻塞
- 不断发起read请求,不阻塞,直到数据准备好,拷贝数据到用户空间阻塞
IO多路复用
- 发起select调用,询问数据是否就绪,不阻塞,数据准备就绪后告诉程序可以查看,则拷贝数据进入用户空间,拷贝过程阻塞
AIO
基于异步和回调机制,应用操作直接返回,内核完成拷贝数据后,告诉线程进行后续操作
输入输出
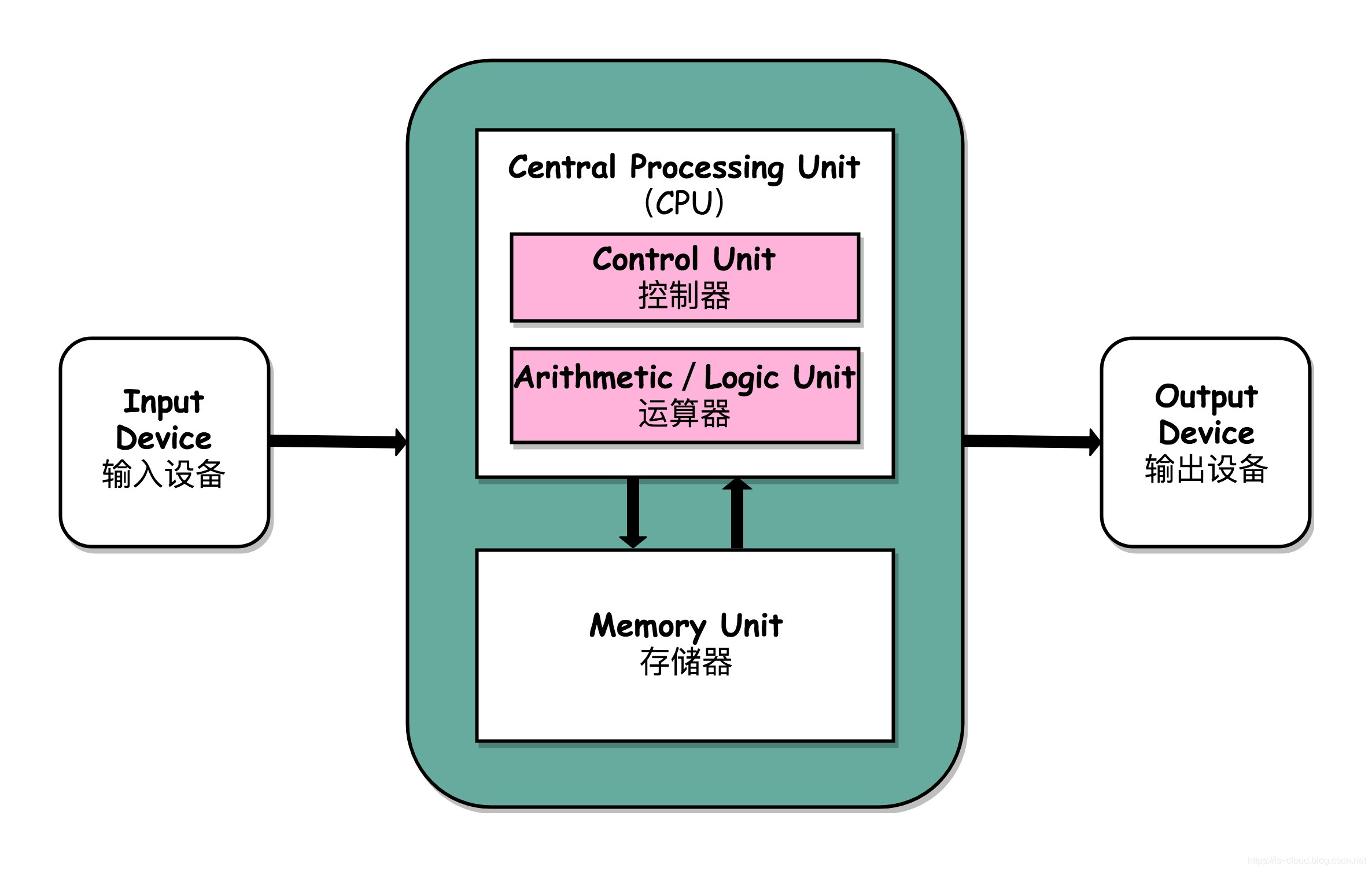
冯诺依曼结构:运算器、控制器、存储器、输入设备、输出设备
IO描述了计算机系统和外部设备之间通信的过程,接触的多的:磁盘IO,网络IO
为了保证操作系统的稳定性和安全性,一个进程的地址空间划分为用户空间和内核空间
平时运行的应用程序都是在用户空间,只有内核空间才能进行系统态级别的有关操作,比如文件管理、进程通信、内存管理等等,我们想要进行IO操作,就一定要依赖内核空间的能力,且用户空间的程序不能直接访问内核空间
当想要完成IO操作时,由于没有这些操作的权限,只能发起系统调用请求操作系统来完成
应用程序发起IO调用后
- 内核等待IO设备准备好数据
- 内核将数据从内核空间拷贝到用户空间
IO模型
同步阻塞IO,同步非阻塞IO,IO多路复用,信号驱动IO,异步IO
JAVA:BIO
blocking IO,同步阻塞IO模型
应用程序发起read调用后,会一直阻塞,直到在内核将数据拷贝到用户空间
在客户端连接有十万,百万的时候,BIO模型是无能为力的,所以需要更高效的IO处理模型应对并发量
JAVA:NIO
Non-blocking / New IO
java Nio于java1.4引入,对应java.nio包,提供Channel,Selector,buffer等抽象
支持面向缓冲的,基于通道的IO操作方法,对于高负载、高并发的(网络)应用,应使用NIO;
java中的NIO,有选择器,可以称为多路复用器,只需一个线程就能管理多个客户端连接,拿到客户端连接后,才会为其服务
IO多路复用模型(select)?同步非阻塞模型(read)?
同步非阻塞
程序反复发起read,过程不阻塞,等待数据从内核空间拷贝到用户空间的时间里,线程依然是阻塞的,直到内核把数据拷贝到内核空间
通过轮询操作,避免了一直阻塞,消耗CPU资源
IO多路复用
程序首先发起select调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程发起read调用,read调用过程(数据从内核态到用户态)还是阻塞的
支持IO多路复用的系统调用有:select、epoll等等
- select调用,内核提供的系统调用,支持一次查询多个系统调用的可用状态,基护所有操作系统都支持
- epoll调用,linux2.6内核,select增强,优化IO执行效率
IO多路复用模型,减少无效系统调用,减少对CPU资源的消耗
JAVA:AIO
AIO就是NIO2,java7引入了NIO2,是异步IO模型
基于事件和回调机制实现,应用操作后会直接返回,不会阻塞,当后台处理完成,操作系统会通知相应的线程进行后续的操作
Netty也尝试使用AIO,但是在linux上性能没多少提升
总结
进程、线程
线程是进程划分成的最小运行单位,一个进程能产生多个线程
进程是资源分配的基本单位,线程是任务调度的基本单位
进程是独立的,统一进程间的线程可能相互影响
线程执行开销小,不利于资源的管理和保护
jvm中的每个线程都有自己的程序计数器、虚拟机栈、本地方法栈
进程状态
创建:在被创建
就绪:等待获取处理器资源
运行:单核CPU下任意时刻只有一个进程运行
阻塞:等待事件、资源、IO
终止:进程结束或者中断
进程通信
信号:通知接受事件发生
消息队列:消息的链表,有特定的格式,存放在内存由消息队列标识符标识,管道和消息队列都是先进先出,存放在内核中,只有内核重启或者删除队列才能真正删除,可以实现消息的随机查询,按照消息类型,克服了信号承载信息少,管道只承载无格式字节流以及缓存区大小受限等缺点
信号量:计数器,多进程的共享数据访问,解决同步问题
共享内存:多个进程可以访问同一块内存空间,依靠同步操作,互斥锁和信号量,最有用的通信方式
套接字:客户端和服务器网络通信,支持TCP/IP的网络通信基本操作单元
管道:父子进程或者兄弟进程通信
有名管道:先进先出,以磁盘文件的方式存在,本机任意进程通信
线程通信
互斥量:只有拥有互斥对象才能访问公共资源,synchronized,lock
信号量:统一时刻一定数量的线程访问同一资源
事件:wait / notify,通知操作保持多线程同步
进程调度
先来先服务:
短作业优先:剩余时间最短的运行到结束
轮训调度:每个进程分配一个时间片
优先级调度:进程分配优先级,相同优先级则先来先服务
多级反馈队列调度:执行队列分层,每层所拥有的时间片不同,用完时间片就会上升的高层,但是只有低层的进程执行完了才能到高层
死锁
多个进程竞争有限的资源,A持有资源1,B持有资源2,此时A想获取对象资源2,B想获取对方的资源1,造成死锁
互斥:资源非共享,必须要等待资源释放
持有等待:进程拥有一个资源等待另一个资源
非抢占:不能抢占资源
循环等待:A等B持有的资源,B等C持有的资源,C等A持有的资源
内存管理
负责内存分配和回收、
地址转换:将逻辑地址转化为物理地址
内存管理机制
连续分配管理方式(块式管理)和非连续分配管理方式(页式管理、段式管理)
块式管理:内存分为固定大小的块,每个块只包含一个进程,程序需要内存就分配一块,很可能产生碎片
页式管理:主存分为大小相等、固定的页的形式,页比块小,提高内存利用率,减少碎片
段式管理:主存分为一段段的,每一段的空间比一页小很多,每段定义一组逻辑信息(主程序段、子程序段、数据段、栈段等),通过段表对应逻辑地址和物理地址
段页式管理:把主存分为若干段,每段分为若干页,段与段之间,段的内部都是离散的
快表和多级页表
分页内存管理中的两个问题:
虚拟地址到物理地址的转化要快
解决虚拟地址空间大,页表也会很大
快表
解决虚拟地址到物理地址的转换速度,在页表方案基础上引入快表加速虚拟地址到物理地址的转换
理解为一种特殊的高速缓冲存储器,内容是页表的一部分或全部内容
由于页表做地址转换,读写内存速度时CPU要访问两次主存,有了快表只需要访问一次高速缓冲存储器,一次主存,这样可加速查找并提高指令执行速度。
- 根据虚拟地址中的页号查快表
- 如果该表在快表中,直接从快表读取相应的物理地址
- 如果该页不在快表,就访问内存中的页表,从页表得到物理地址,同时将页表中的映射表项添加到快表
- 快表填满后,又要登记新页时,就按照一定的淘汰策略淘汰快表中的一个页
==多级页表==
避免把全部页表放入内存中占用过多空间,特别是不需要的页表
分页和分段
共同点:
- 分页和分段都是为了提高内存利用率,减少内存碎片
- 页和段都是离散存储,但是页和段的内存是连续的
区别:
- 页大小固定,由操作系统决定;段的大小不固定,取决运行的程序
- 分页是满足操作系统内存管理的需求,段是逻辑信息的单位,在程序中体现为代码段、数据段,满足用户需要
逻辑地址和物理地址
编程只是和逻辑地址打交道,C语言中指针里的数值就是内存中的一个地址,这个地址就是逻辑地址,由操作系统决定
物理地址是真实物理内存中的地址
CPU寻址和虚拟地址空间
虚拟寻址中,CPU中的内存管理单元将虚拟地址翻译成物理地址,才能访问真实的物理地址
虚拟地址空间
没有虚拟内存空间时,程序都是直接访问和操作物理内存,
- 用户程序可以任意访问内存,容易破坏操作系统
- 运行多个程序可能会导致两个程序操作同一地址
虚拟内存优势:
- 程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区
- 程序使用虚拟地址访问大于可用物理内存的内存缓存区。当物理内存供应量变小,内存管理器会将物理内存页(通常4KB),保存到磁盘文件,数据和代码页会根据需要在物理内存和磁盘之间移动
- 程序隔离,不同的进程使用虚拟地址批次隔离,无法修改另一进程的物理内存
页面置换算法
内存页面置换算法:
FIFO先进先出
LRU(Least Recently Used)最近最少使用,淘汰最久没访问过的(横坐标往前看队列长度个,淘汰他),主要看时间
LFU(least frequently used)最不经常使用,主要看频率
CLOCK时钟算法,页面初始为1,循环链表中,指针顺时针旋转,指到页面为0就替换,指到页面为1就置为0,使用到则置为1
OPT最佳页面置换算法:淘汰永不使用的,最长时间不访问的,但是无法实现预测
LRU,最近最少使用,把数据加入一个链表中,按访问时间排序,发生淘汰的时候,把访问时间最旧的淘汰掉。
比如有数据 1,2,1,3,2
此时缓存中已有(1,2)
当3加入的时候,得把后面的2淘汰,变成(3,1)
LFU,最近不经常使用,把数据加入到链表中,按频次排序,一个数据被访问过,把它的频次+1,发生淘汰的时候,把频次低的淘汰掉。
比如有数据 1,1,1,2,2,3
缓存中有(1(3次),2(2次))
当3加入的时候,得把后面的2淘汰,变成(1(3次),3(1次))
区别:LRU 是得把 1 淘汰。
LRU对于循环出现的数据,缓存命中不高,LFU对于交替出现的数据,缓存命中不高
虚拟内存
简介
软件的内存可能很大,超过了物理内存,虚拟未存为每个进程提供一个一致的,私有的地址空间,让每个进程认为自己拥有一片连续完整的内存空间,将内存扩展到硬盘
实际上,它被分割成多个物理内存碎片,还有部分暂时存储在外部磁盘上,在需要时数据交换,大型程序编写变得更加容易,对物理内存使更有效率
局部性原理
时间局部性:如果数据、指令访问了,近期可能会再次访问,for循环
空间局部性:如果数据访问了,存储空间附近的数据也可能访问,
只装部分程序到内存就能运行
实现:
时间局部性:将近来使用的指令和数据保存到高速缓存存储器中,采用高速缓存的层次结构实现
空间局部性:使用较大的高速缓存,将预取机制集成到高速缓存控制逻辑中实现
虚拟内存建立“内存——外存”两级存储器结构,利用局部性原理实现高速缓存
虚拟存储器 / 虚拟内存
基于局部性原理,只需要将程序的一部分装入内存,外存比内存大
程序运行时访问的信息不在内存时,操作系统将需要的部分调入内存
将暂时不使用的内容换到外存上,计算机就像提供了比实际内存更大的存储器–虚拟存储器
以时间换空间,用CPU计算的时间,页的调入调出花费的时间换来更大的空间支持运行
虚拟内存实现
虚拟内存的实现需要建立在离散分配的内存管理方式的基础上
请求分页存储管理:
建立在分页管理之上,为了支持虚拟存储器功能,增加了请求调页功能和页面置换功能
作业开始运行前,仅装入当前要执行的部分段即可运行,如果运行时发现要访问的页面不在存在,处理器通知操作系统按照页面置换算法将页面调入主存,将暂不使用的页面置换到外存中。
请求分段存储管理:
建立在分页存储管理之上,增加了请求调段功能、分段置换功能
作业开始运转前,仅装入要执行的部分段即可运行,执行过程中,使用请求调入中断动态装入要访问但是不在内存的程序段
内存空间满,又需要装入新段,根据置换功能调出段
请求段页式存储管理:
实现方式相同点:
都需要一定内存和外存
缺页中断:需要执行的指令或者要访问的数据没在内存,则通知操作系统将相应的页面或段调入内存
逻辑地址到物理地址的变换
请求分页和分页存储管理的区别:
请求分页存储管理建立在分页管理之上,根本区别:是否将程序所需的全部地址空间装入主存
请求分页存储管理能提供虚拟存储
MySQL
关系型数据库,支持事务
基本操作
结构
# 数据库
create database dbname;
drop database dbname;
use dbname;
# 表
create table tablename(
'id' int auto_increment,
'name' varchar(40) not null,
primary key('id'),
unique index indexName (username(length) )
);
drop tablename;
alter table tableName modify id is not null;索引
SHOW INDEX FROM table_name;
create unique index indexname on tablename(col1, col2);
alter table tablename add indexName(columnName);
alter table tablename add primary key(id);
drop index indexName on tableName;表
select * from table;
update table set name = 'name';
delete from table where id = 1;
insert into table(name, age) values('name', 'age')数据库架构
逻辑架构图分层
- 处理连接、授权认证、安全等
- 编译优化SQL
- 存储引擎
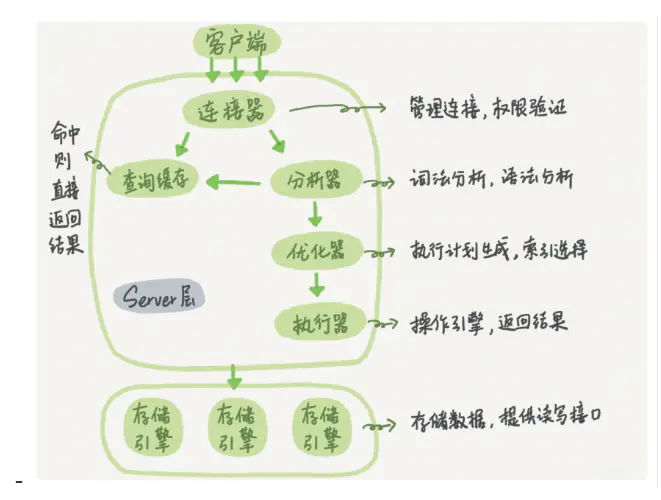
MYSQL执行过程
- 检查语句是否有权限,没权限直接返回错误信息,有权限查询缓存
- 没有缓存,进行词法、语法分析,提取select等关键信息,然后判断语法是否正确
- 优化器确定执行方案进行权限校验,没有权限直接返回错误信息,有权限则调用数据库引擎接口,返回执行结果
存储引擎
命令
# 查看 MySQL 提供的所有存储引擎
show engines;
# 查看 MySQL 当前默认的存储引擎
show variables like '%storage_engine%';
# 查看表的存储引擎
show table status like "table_name" ;区别
5.5.前,使用的MyISAM 不支持事务和行级锁,崩溃后无法安全恢复
InnoDB 提供事务支持,具有提交和回滚事务能力
支持外键
能够安全恢复(redo log)
支持MVCC(多版本并发控制), 可以看作是行级锁的一个升级,可以有效减少加锁操作,提供性能。
myisam
如果都是插入和查找,对事务完整性、并发不高,不错的选择
查找快:数据和索引文件分开,每棵B+树叶子节点存储数据地址,能够直接定位到数据,而InnoDB存储的是主键ID,需要根据主键ID再次查找树获取具体信息。
事务
要么都执行,要么都不执行
转账,A的余额减少1000,B的余增加1000
开启事务,提交事务
ACID
原子性 Atomicity,一致性 Consistency,隔离性 Isolation,持久性 Durability
原子性: 事务是最小单位,不可分割,确保事务要么都成功,要么完全不起作用
一致性:事务前后,数据保持一致, 转账中:两人的总额不变
隔离性:事务不互相干扰,并发事务之间相互独立
持久性:一个事务被提交后,数据的改变是持久的,数据库发生故障也不能有影响
实现
原子性:undo log(回滚日志)
一致性:
隔离性:锁机制(默认可重复读)、MVCC
持久性:redo log(重做日志)
隔离级别
事务A进行插入、by id更新操作
事务B分别进行两组count(*)、select by id
- 可重复读时,B执行到一半A提交
- 第二次count增加了(幻读,使用快照读,第二次读与第一次select的值一致,但是对插入的值无效,update、delete、insert时采用当前读)
- 第二次select还是一样的值
- 读已提交,B执行到一半A提交
- 第二次count增加(幻读)
- 第二次select查到新的值(不可重复读)
- 读未提交,B执行到一半
- 第二次count增加(幻读)
- 第二次select查到新的值
- 如果事务B成功提交(不可重复读)
- 如果事务B回滚(脏读)
begin; -- 事务1
insert into table1 (somevaue); -- 随意写的伪sql
update table2 set aa = aa + 1 where id = 1;
commit;
begin; -- 事务2
select count(*) from table1; -- 第一次读count
select aa from table2 where id = 1; -- 第一次读aa
-- 假设在这个点 事务1成功提交
select count(*) from table1; -- 第二次读count
select aa from table2 where id = 1; -- 第二次读aa
commit;- read-uncommitted(读取未提交):读取未提交的数据变更,可能导致脏读,幻读和不可重复读
- 事务2中 第二次读count得到的值和第一次读count得到的值不一样(因为事务1新增了一条数据),这叫幻读,不隔离新增的数据。
- 事务2中 两次读 aa 得到的值是不一样的(此时事务1未提交),对最新版本的值可见,不隔离已经存在的数据。 不可以重复读,读到的数据是不一样的。
- 如果此时事务1因为其他原因回滚了,事务2第二次读到的数据是无意义的,因为修改没有发生(回滚了),这叫脏读 。
- read-committed(读取已提交, 脏读):读取并发事务已经提交的数据,可以防止脏读,但是幻读和不可重复读仍可能发生
- 事务2中
第二次读count得到的值和第一次读count得到的值不一样(因为事务1新增了一条数据),这叫幻读,不隔离新增的数据。 - 事务2中
第一次读aa和第二次读aa得到的值是不一样的,对刚提交的值可见,不隔离已经存在的数据。 不可以重复读,读到的数据是不一样的(如果成功修改)。
- 事务2中
- repetable-read(可重复读, 不可重复读,丢失修改):对同一字段的多次读取结果是一致的,除非是数据被自身事物修改,解决部分幻读(解决读,但是对于修改的操作存在幻读)
- 事务2执行到一半时,事务1 插入成功提交
- 事务2中 第二次读count得到的值和第一次读count得到的值不一样(因为事务1新增了一条数据),这叫幻读,不隔离新增的数据。
- 事务2中 第一次读aa 和第二次读aa得到的值是一样的,对刚更新的值不可见,隔离已经存在的数据。 可以重复读,读到的数据都是一样的。
- serializable(可串行化):最高隔离级别,所有事物依次逐个执行
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
默认可重复读
分布式事物下一般使用serializable可串行化隔离级别
并发
并发问题
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
脏读(Dirty read): ==读取其他事务未提交的数据==(解决:读已提交)
当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
不可重复读(Unrepeatableread): ==一个事务两次读的中间,另一个事务修改了,导致第二次读取到的数据不一样;==(解决:可重复读)
指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
幻读(Phantom read): ==事务一在两次读之间,事务二插入或删除了数据,事务一发现多了数据,和产生幻觉一样==(解决:可串行化、可重复读&MVVC)
幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
*丢失修改(Lost to modify): * ==A事务访问数据,B事务也访问了数据,A事务对数据修改后,B事务也修改了,导致第一个事务的修改无效。==(解决:??)
指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。
默认可重复读
https://www.cnblogs.com/liyus/p/10556563.html
事务A读,事务B插入,事务A更改B插入的数据更改成功
说明对于修改操作存在幻读
原因:
select 默认快照读
快照读中,对事务中的select进行缓存,所以之后的select都是一样的,但是如果开启事务A后一直没操作,B事务insert了数据,A事务依然能读取到最新数据
对于会修改的操作(insert/update/delete)采用当前读,最新这几个操作会读取最新的记录,即使别的事务提交也可以查询到
如:A事务update一条记录,但是B已经delete并且commit,如果update就会冲突,所以在update的时候就需要知道最新数据
如果select当前读,加锁
where ? lock in share mode;
where ? for update;
begin要在对数据进行增删改查后才开启一个事务
锁
数据库有并发事务时,可能会产生数据脏读、不可重复读、幻读、丢失修改,需要一定的机制保证访问的次序,可以通过锁来实现
类型
悲观乐观锁
悲观:认为每次事务的值都会被其他事务修改,所以每次都加锁
乐观:认为事务的值不会被其他事务修改,不加锁
- 更新时判断期间是否有修改,写前取出版本号后加锁,版本号机制和==CAS==算法
读锁、写锁
(共享锁)是为了让当前事务读一行数据,可以多次加锁
select * from user where id = 1 LOCK IN SHARE MODE(排它锁)是为了让当前事务修改或删除一行数据,只能有一个写,不能有读
select * from user where id = 1 FOR UPDATE;意向锁
使得行锁和表锁能够共存,是表级别的锁,说明事务稍后会对表中的数据行添加哪种类型的锁(共享、独占)
记录锁
索引记录上的锁,select .. where c1=10 for update;会组织其他事务对c1=10的数据行进行插入、更新、删除等操作,
总是锁定索引记录,如果没有定义索引,就会锁定隐式的“聚类索引”
间隙锁
行锁实现
InnoDB行锁是通过给索引加锁来实现的,如果没有索引,InnoDB会通过隐藏的聚簇索引来对记录进行加锁(全表扫描,也就是表锁)
在没有索引时,不满足条件的数据行会有加锁又放锁的耗时过程(为了效率考量,MySQL做了优化,对于不满足条件的记录,会放锁,最终持有的,是满足条件的记录上的锁。但是不满足条件的记录上的加锁/放锁动作是不会省略的)
索引分为主键索引和非主键索引两种。如果一条sql语句操作了主键索引,MySQL就会锁定对应主键索引;如果一条语句操作了非主键索引,MySQL会先锁定非主键索引,再锁定对应的主键索引。
MVCC
https://www.jianshu.com/p/c51ba403ce07
多版本并发控制机制,锁机制可以控制并发操作,但是系统开销较大,MVCC在多数情况下可以代替行级锁,降低系统开销
同一份数据临时保留多版本,实现并发控制
实现
通过保存数据在某个时间点的快照来实现,不同的存储引擎对MVCC实现不同,典型的有乐观并发控制和悲观并发控制
InnoDB的MVCC是通过在每行记录保存两个隐藏的版本号(创建/删除的事务版本号时间戳或者事务 ID)实现的,每次开启一个事务,版本号就会递增
Select
查询的条件
- 查找版本早于当前事务版本的数据行
- 行的删除版本未定义或者大于当前事务的版本号
Delete
InnoDB会为删除的每一行保存当前系统的版本号(事务的ID)作为删除标识.
Update
它不会直接用新数据覆盖旧数据,而是将旧数据标记为过时(obsolete)并在别处增加新版本的数据
索引
是什么,为什么,怎么样
相当于查字典的目录
优点:
- 加快检索速度,减少检索量
- 唯一性索引,保证数据唯一性
缺点:
- 创建和维护耗费时间,增删改会动态修改索引
- 索引使用物理文件存储,耗费空间
索引分类
一级索引
主键索引:特殊的唯一索引,一个表只能有一个主键,不允许有空值
- 没有指定主键,将唯一索引字段当做主键,否则创建6Byte的自增主键
二级索引
普通索引:加快查询数据
唯一索引:索引列的值必须唯一,但允许有NULL
- 大部分是为了数据唯一性
前缀索引:对文本前几个字符创建索引,数据小
全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较,ngram全文解析器
Other
联合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用
- (最左前缀匹配原则)最常用的放在左边,依次递减,index(a,b,c),先用a,a一样才用b
减少随机IO、过滤出越少的数据,从磁盘读入的数据更少
- 区分度高的在左侧
- 字段长度小的放左侧(字段小,一页的数据大,IO性能好)
- 最频繁的放在联合索引左侧
聚簇索引
索引和数据一起存放,主键为聚簇索引
优点:
- 查找速度快,B+树是多叉平衡树,叶子结点有序,定位到索引的节点,就找到了数据
缺点:
- 依赖有序的数据:B+树时,如果数据不是有序的,在插入时需要排序,如果是字符串或者UUID,插入和查找就会变慢
- 更新代价大:数据被修改,索引也修改,所以主键索引一般不可修改
非聚簇索引
索引结构和数据分开存储,二级索引属于非聚簇索引
优点:
- 更新代价小,叶子节点不存放数据
缺点:
- 依赖有序的数据
- 可能会二次查询(回表):查到索引对应的主键,需要根据指针或者主键再次查询真正的数据
- 如果select name条件为name,就不需要回表
覆盖索引
覆盖索引要查询的字段刚好是索引的字段,则无需回表
基本数据结构
Mysql索引使用的是B+树
为什么B+树
Hash(无法范围查询,hash冲突,插入慢,不能排序,不能模糊以及多列索引的最左前缀匹配)
搜索二叉树(存在不平衡,IO)
红黑树(存在右倾,IO操作多)
平衡二叉树(一个节点只有一个数据,IO慢)
B树(节点存储数据库一行的数据,列增加,空间占用大)
B+树优点
磁盘读写更快:每个节点存储的节点数据多(节点默认16kb,不存数据能存更多节点),降低树的高度(高度越高,则IO越多),具体信息放在叶子节点,非叶子节点存储字段索引+指针,占用空间小,读入内存的多
查询更稳定:非终结点并不是指向文件内容的节点,而是叶子节点关键字的索引(冗余),索引找到任何一个关键字都要走完一条路,路径相同,所以查询效率相当
便于遍历和范围查找:数据都在叶子节点,叶子结点横向链接,扫库只需要遍历叶子节点,如果是B树则要中序遍历
中间节点存的是字段索引+指针,Innodb叶子节点存的是数据
而myisam存的是数据地址
https://zhuanlan.zhihu.com/p/113917726?utm_source=qq&utm_medium=social&utm_oi=1132438455900327936
数据结构模拟: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
HASH
散列算法,将key通过哈希函数变化为固定长度的key地址,通过这个地址找到具体的数据
如果hash值一样,就通过拉链法解决冲突,通过链表操作数据
缺点:
范围查询:where id > 3,如果使用hash则需要将数据都找出来加载到内存筛选
插入:hash冲突,速度慢
二叉查找树
二叉查找树的时间复杂度是 O( log2(n) ),可以范围查找
缺点:会退化成线性链表,时间复杂度变为O(n)
==红黑树==
通过树节点的自动旋转和调整,让二叉树保持平衡
平衡二叉树性质
所有左右子树的高度相差不超过 1 的树为平衡二叉树
平衡因子
红黑树性质
- 节点是红色或黑色。
- 根是黑色。
- 所有叶子都是黑色(叶子是NIL节点)。
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
AVL树(平衡搜索二叉树)
AVL 树不存在红黑树的“右倾”问题。也就是说,大量的顺序插入不会导致查询性能的降低,这从根本上解决了红黑树的问题。
优点:
- 不错的查找性能(O(logn)),不存在极端的低效查找的情况。
- 可以实现范围查找、数据排序。
缺点:
数据库查询瓶颈在磁盘IO,AVL树中每个数节点只存储一个数据,一次IO只能从磁盘中取出一个节点上的数据加载到内存中,所以我们要减少磁盘IO次数
磁盘IO特点:读取1B和1KB(1KB=1024B字节)数据消耗的时间基本一样(柱面、磁头、扇区),所以一个树节点尽量多的存储数据,一次IO加载更多的数据到内存,这就是B、B+树的原理
1B=8b 1KB=1024B
1字节 = 8位
java一个char两个字节
B树
平衡的多叉树
每个节点限制最多存储两个 key,一个节点如果超过两个 key 就会自动分裂

尽可能在一次磁盘 IO 中多读一点数据到内存。这个直接反映到树的结构就是,每个节点能存储的 key 可以适当增加。

- 优秀检索速度,时间复杂度:B 树的查找性能等于 O(h*logn),其中 h 为树高,n 为每个节点关键词的个数;
- 尽可能少的磁盘 IO,加快了检索速度;
- 可以支持范围查找。
节点存储值,占用空间大,索引不重复
B+树
B的升级,充分利用节点的空间,查询更稳定,完全接近于二分查找

第一,B 树一个节点里存的是数据,而 B+树存储的是索引(地址),所以 B 树里一个节点存不了很多个数据,但是 B+树一个节点能存很多索引,B+树叶子节点存所有的数据。
第二,B+树的叶子节点是数据阶段用了一个链表串联起来,便于范围查找。
B+树节点存储的是索引,在单个节点存储容量有限(16KB)的情况下,单节点也能存储大量索引,使得整个 B+树高度降低,减少了磁盘 IO
B+树的叶子节点是真正数据存储的地方,叶子节点用了链表连接起来,这个链表本身就是有序的,在数据范围查找时,更具备效率。
解析
MyISAM 虽然数据查找性能极佳,但是不支持事务处理。Innodb 最大的特色就是支持了 ACID 兼容的事务功能,而且他支持行级锁
Innodb
innodb,innodb 引擎把数据和索引放在同一个文件里了,这叫做聚集索引方式
- frm:创建表的语句
- idb:表的数据+索引文件
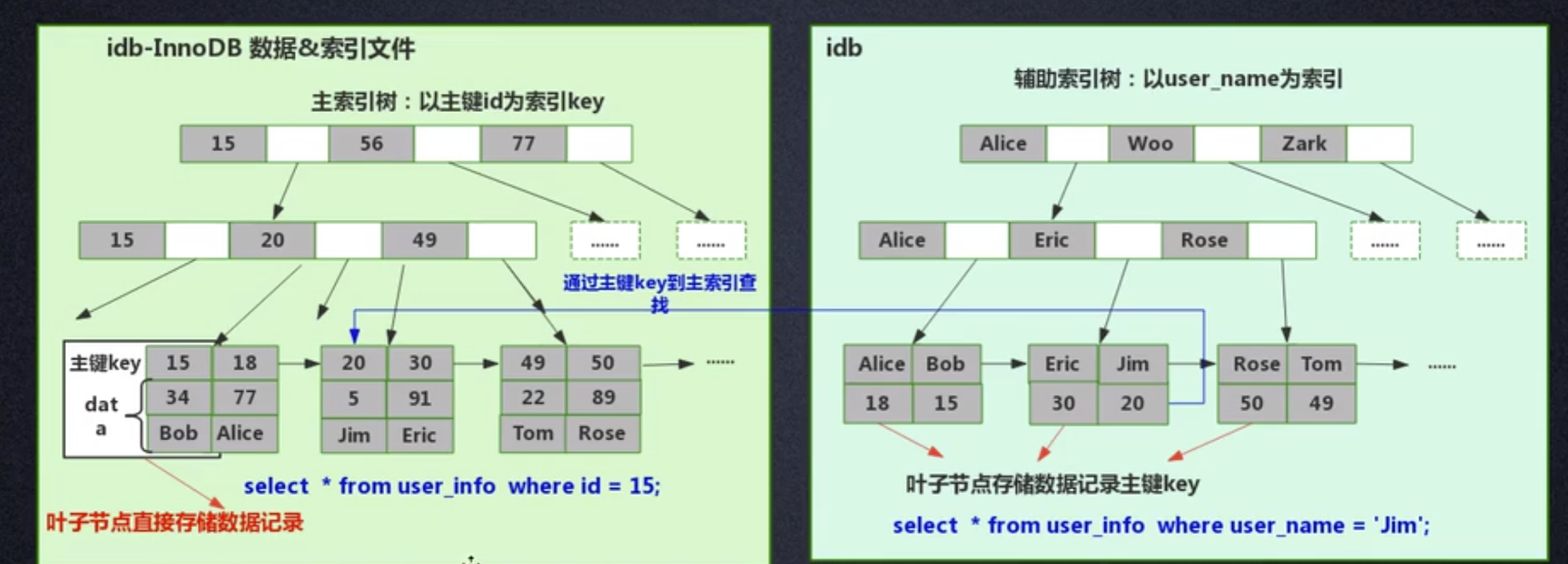
innodb是聚集索引,数据和索引存储在同一个文件中,根据主键ID建立索引B+树
字段添加索引会建立索引B+树,但是节点里存的是字段key索引,叶子节点存的是主键,通过字段索引找到主键key,通过key找对应的数据
- InnoDB 需要节省存储空间。一个表里可能有很多个索引,InnoDB 都会给每个加了索引的字段生成索引树,存在数据冗余
Myisam
myisam,MyISAM 引擎把数据和索引分开了,一人一个文件,这叫做非聚集索引方式
- frm:创建表的语句
- myd(data):数据文件
- myi(index):索引文件
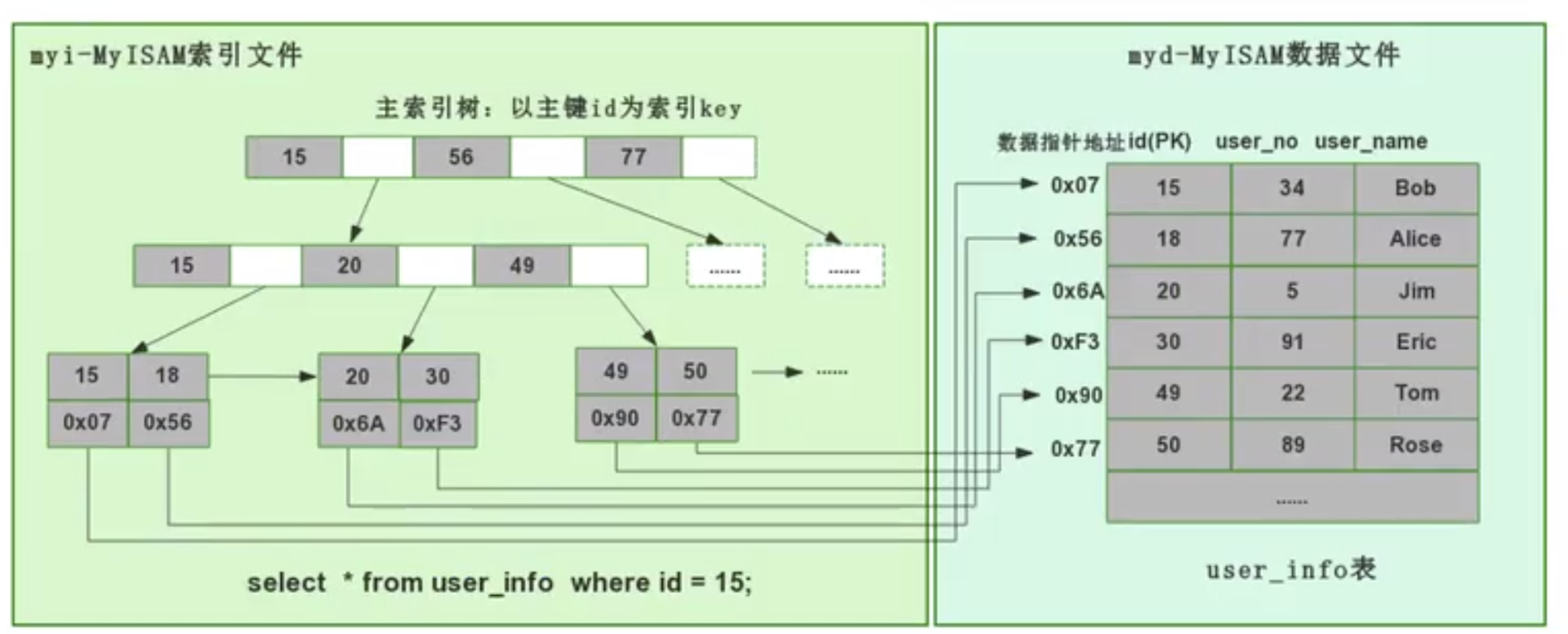
myisam以主键作为key建立索引B+树,树的节点存对应数据的物理地址,通过这个地址从数据文件中定位到数据记录,字段添加索引也是这样
MyISAM 查询性能更好
- MyISAM 直接找到物理地址后就可以直接定位到数据记录,但是 InnoDB 查询到叶子节点后,还需要再查询一次主键索引树,才可以定位到具体数据
- 等于 MyISAM 一步就查到了数据,但是 InnoDB 要两步,那当然 MyISAM 查询性能更高。
使用
--- 添加主键
alter table 'table_name'
add primary key('column')
--- 唯一
add unique('column')
--- 普通
add index index_name('column')
--- 全文
add fulltext('column')
--- 多列
alter table 'table_name' add index index_name ('column1', 'column2')最佳实践
SQL耗时么?统计过慢查询么?慢查询如何优化?
养成explian分析习惯
- 索引是否命中
- 不必要的字段/数据
- 优化SQL结构
- 表数据量大,分表
模糊查询
禁止左模糊(%xxx)或者全模糊
原因:索引文件具有B-Tree的最左前缀匹配特性,如果左边的值未确定,则无法使用该索引
外键和级联
不得使用外键和级联,应该由应用层解决
以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。
外键与级联更新适用于单机低并发,不适合分布式、高并发集群;
级联更新是强阻塞,存在数据库更新风暴的风险;
外键影响数据库的插入速度
坏处
- 增加复杂性
- 每次delete或者update都需要考虑外键约束,导致开发很痛苦,测试不方便
- 需求有变化时,不需要有关联就很麻烦
- 外键因为需要请求对其他表内部加锁而容易出现死锁情况
- 分库分表外键无法生效
好处
- 保证数据的一致性和完整性
- 级联操作方便,减少程序代码量
查询优化
避免where != 或 <>
避免where or
不要出现select *
避免where进行null判断
字段要求
not null
null会更多字节,不可预期的情况
固定长度用char
密码散列、盐、身份证号等固定长度的使用char,节省空间,提高检索效率
varchar和char
varchar变长,占用空间为实际字符长度+1,最后一个字符(asscii码,字符存放2个字节,UTF8,字符3个字节)存储多长空间
varchar(10)和int(10)
varchar申请的空间长度,int10代表展示的长度,通过一个参数设置生效
@Transactional
不要滥用,事务会影响数据库的QPS,使用需要考虑各方面的回滚方案,缓存回滚,搜索引擎回滚、消息补偿,统计修正等
索引实践
合不合适
不适合的
- 较频繁的作为查询条件的字段应该创建索引;
- 唯一性不好的字段不适合单独创建索引,即使该字段频繁作为查询条件;
- 更新频繁的字段不适合创建索引。
适合使用索引
- 表的主关键字,唯一索引、唯一约束
- 与其他表关联(join、where)的字段
- (order by,group by、distinct、count)排序的字段、统计或分组的字段
- 多个都有,建议用联合索引
- limit慢
注意
创建索引:列的值少(如性别只有男、女、未知),不要创建,影响更新速度,多度索引
复合索引:mysql查询每次只能使用一个索引,select * from users where area=’beijing’ and age=22,age和area应当创建复合索引,最常用的放在左侧
排序的索引问题
查询只使用一个索引,如果where已经使用索引,order by就不会使用,因此尽量不要使用排序操作
尽量不要包含多个列的排序,如果需要,就给列添加复合索引
特大型表:维护开销很大,不建议建立
使用逻辑主键:与业务无关,自增ID(如果是UUID,大小不确定,会造成数据移动,插入效率下降,占用空间大),不使用业务主键
删除不用的索引:长期不使用的索引影响性能
- 未使用过:select * from sys.schema_unused_indexes;
- 冗余:select * from sys.schema_redundant_indexes;
索引列顺序:
减少随机IO、过滤出越少的数据,从磁盘读入的数据更少
- 区分度高的在左侧
- 字段长度小的放左侧(字段小,一页的数据大,IO性能好)
- 最频繁的放在联合索引左侧
索引失效
MYSQL分析全表扫描更快时
!=
like:like “%aaa”不使用索引,使用”aaa%”
not in:not i不会使用索引,使用not exists
where 字段添加函数:无法命中索引
复合索引不会包含有Null的列:复合索引只要有一列含有null,则该列对于无效,所以不要让字段默认值为null,
复合索引,前面为范围查询,无法使用索引
隐式转化,字段String要转int
开发规范
预编译
重复利用sql执行计划,减少sql编译时间,解决动态SQL注入问题,只传参数,比传递SQL更高效
数据库权限
不同应用应不同权限,禁止跨库查询
- 为数据库迁移和分库分表准备
- 降低业务耦合
- 避免权限太大
select [字段]
- 消耗CPU和IO、网络带宽
- 无法使用覆盖索引
- 减少表结构变化带来的影响
insert
insert要指定字段
子查询换成join
通常子查询在in中,不包含(union、group by、order by、limit)时,转为关联查询优化
原因:
子查询结果集不能使用索引,其存放在临时表中,不论是内存临时表还是磁盘临时表都不存在索引,消耗CPU和IO
避免JOIN太多
mysql存在关联缓存,缓存大小通过 join_buffer_size 设置
同一个sql join多个表,多个关联缓存,占用内存大
最多关联61个表,建议5个
in代替or
in不要超过500,有效利用索引,or很少使用索引
禁止order by rand()
会将所有数据装入内存,随机生成值排序,如果满足条件的数据量很大,就消耗大量CPU和IO
推荐在程序中获取随机值,再到数据库中获取数据
where禁止函数
where date(create_time)='20190101'union all 、union
没有重复值用 union all
- union 将两个表数据都放到临时表再去重
- union all 不会去重
拆分大SQL
大SQL逻辑复杂,消耗CPU计算
mysql一个sql只能用一个CPU
拆分后可以通过并行执行提高执行效率
行为规范
超过100万行的批量写,要分批
主从延迟
大批量写执行时间长,只有主库完成,从库才能执行,延迟高
binlog为row格式,产生大量日志
row格式二进制数据,记录每一行的修改,日志传输和恢复时间长,主从延迟
大事务
事务中操作,数据大批量锁定,大量阻塞
长时间阻塞占用连接,其他应用无法连接数据库
大表用 pt-online-schema-change 修改表结构
- 避免大表修改产生的主从延迟
- 避免在对表字段进行修改时进行锁表
对大表数据结构的修改一定要谨慎,会造成严重的锁表操作,尤其是生产环境,是不能容忍的。
pt-online-schema-change 它会首先建立一个与原表结构相同的新表,并且在新表上进行表结构的修改,然后再把原表中的数据复制到新表中,并在原表中增加一些触发器。把原表中新增的数据也复制到新表中,在行所有数据复制完成之后,把新表命名成原表,并把原来的表删除掉。把原来一个 DDL(数据库、表、DML数据操作) 操作,分解成多个小的批次进
行。
禁止程序super权限
- 当达到最大连接数限制时,还运行 1 个有 super 权限的用户连接
- super 权限只能留给 DBA 处理问题的账号使用
- 程序使用数据库账号只能在一个 DB 下使用,不准跨库
- 程序使用的账号原则上不准有 drop 权限
性能测试
原文链接:https://www.cnblogs.com/tufujie/p/9413852.html
Explain
id: 选择标识符
select_type: 表示查询的类型
table: 输出结果集的表
partitions: 匹配的分区
type: 表示表的连接类型
possible_keys: 表示查询时,可能使用的索引
key: 表示实际使用的索引
key_len: 索引字段的长度
ref: 列与索引的比较
rows: 扫描出的行数(估算的行数)
filtered: 按表条件过滤的行百分比
Extra: 执行情况的描述和说明
type
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
ref:哪些列或常量被用于查找索引列上的值
eq_ref:多表连接中使用primary key或者 unique key作为关联条件
range:只检索给定范围的行,使用一个索引来选择行
index:只遍历索引树
ALL:遍历全表以找到匹配的行
NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
select_type
(1) SIMPLE (简单SELECT,不使用UNION或子查询等)
(2) PRIMARY (子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION (UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION (UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT (UNION的结果,union语句中第二个select开始后面所有select)
(6) SUBQUERY (子查询中的第一个SELECT,结果不依赖于外部查询)
(7) DEPENDENT SUBQUERY (子查询中的第一个SELECT,依赖于外部查询)
(8) DERIVED (派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY (一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
实战
如何SQL优化
优化表结构(使用数字,使用varchar)
优化查询(避免 != 、 <> 、 or 、 select * 、字段 is not null)
索引优化(使用组合索引、查询条件和order by建立索引)
数据库CPU飙升
- top,是否是mysqld
- 是,show processlist,找到消耗资源的sql
- 该sql是否在计划中,索引是否缺失,数据量是否太大
- kill掉不正常的线程,观察CPU是否下降
- 调整索引、SQL、内存参数
- 重新跑SQL
也有可能是大量的session进入,导致cpu飙升,可以限制连接数
主从延迟
主从复制:
- 主库更新事件写入binlog
- 从库发起连接,连接到主库
- 主库创建binlog dump thread,将binlog发送到从库
- 从库启动后,创建I/O线程,读取主库传过来的binlog内从写入relay log
- 创建SQL线程,从relay log读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave到db
延迟原因:
一个服务器开放N个链接是给客户端来连接的,这样会有大并发的更新操作,但是服务器里读取binlog的线程只有一个,当某个sql在服务器上执行的时间稍长,或者因为某个sql要进行锁表,就会导致主服务器SQL大量积压,未同步到服务器里
分库分表
水平分库:以字段为依据,按照策略(hash、range等),将库中的数据拆分到多个库中
水平分表:以字段为依据,按照策略(hash、range等),将一个表中的数据分到多个表中
垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中
垂直分表:以字段为依据,按照字段活跃性,将表字段拆分到不同的表(主表和扩展表)
水平切分:
按数值范围(userid 1~9999)
- 优点
- 单表大小可控
- 便于水平扩展,只要添加节点
- 范围查找时,可以快速定位查询
- 缺点
- 热点数据成瓶颈,例如,按时间片分片,一段时间段内的数据可能频繁读写,其他的用的少
数值取模
一般采用hash取模
优点
- 分片均匀,不容易出现热点和并发瓶颈
缺点
- 集群扩容,需要迁移旧数据(使用一致性hash算法能避免)
- 跨分片查询的复杂问题,查询条件不带主键,无法定位数据库,需要4个库发起查询,在内存中合并
分库分表中间件:
sharding-jdbc mycat
带来的问题:
- 事务:分布式事务
- 跨节点join:分两次查询
- 跨结点count,order by,group by以及聚合函数的问题:分别在各个节点得到结果后再应用程序端进行合并
- 数据迁移,容量规划,扩容
- ID:不能自增,考虑UUID
- 跨分片的排序分页问题
什么时候切分
能不切片就不切片,避免过度设计和过早优化
数据量大,正常运维影响业务访问
业务发展,对字段垂直拆分(user表,last_login_time频繁更新,拆分出去,personal_info占用空间大,访问少,拆分出去)
数据量增长快
Redis
C语言开发的数据,数据存储在内存中,读写速度很快,多用于缓存,也可以用来做分布式锁,甚至是消息队列
redis和memcached
有丰富的数据类型
支持持久化
内存使用完可以放在磁盘上
数据类型
String(用户访问次数、点赞转发、分布式session等)
list(关注列表、粉丝列表)
hash(存储对象)
set(共同好友)
- sinter交集
sort set(排行榜、投票系统)
geospatical地理位置(附近的人,定位,打车)
bitmaps(打卡)
缓存穿透
查询不存在的数据
解决:缓存null,布隆过滤器(散列函数,映射成数组的k个点,判断存不存在只需要看是不是这些点都为1)
缓存雪崩
缓存同一时间集体失效
解决:随机缓存失效时间,永不失效
缓存击穿
key过期,并发访问数据库
解决:加锁
计算机网络
OSI、TCP/IP、五层协议
TCP/IP: 应用层、运输层、网际层IP、网络接口层
五层协议: 应用层、运输层、网络层、数据链路层、物理层

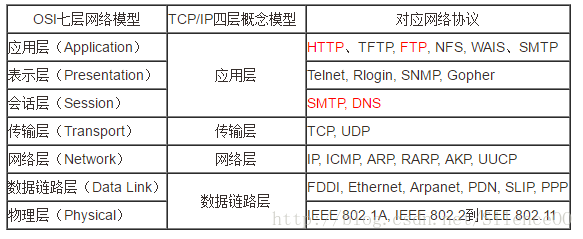
| 层名 | 单位 | 内容 | 协议 |
|---|---|---|---|
| 物理层 | 比特 | 定义物理设备标准 | |
| 数据链路层 | 帧 | 如何格式化数据进行传输 | |
| 网络层 | 数据报 | 提供主机连接和路径选择 | |
| 运输层 | 报文段/用户数据报 | 定义协议和端口号 | |
| 会话层 | 通过运输层建立数据传输的道路 | ||
| 表示层 | 确保应用层发送的信息能够被另一个系统的应用层读取 | ||
| 应用层 | 报文 |
应用层
应用服务通信,HTTP、DNS、SMTP邮件发送、POP邮件存取、FTP文件传输、Telnet、SSH
传输层
负责两台主机进程之间的通信提供通用的数据传输服务
传输控制协议TCP:提供面向连接,可靠的数据传输服务
用户数据协议UDP:提供无连接的,尽最大努力的数据传输服务(不保证数据传输的可靠性)
网际层
分组在网络的活动
封装数组成分组/包、路由选择
流量控制、拥塞控制、差错控制
网络接口层
处理物理接口、ARP(地址解析协议)和RARP(逆地址解析协议),转换IP层和网络接口层使用的地址。
TCP
TCP与UDP区别
TCP:传输控制协议
UDP:用户数据报协议
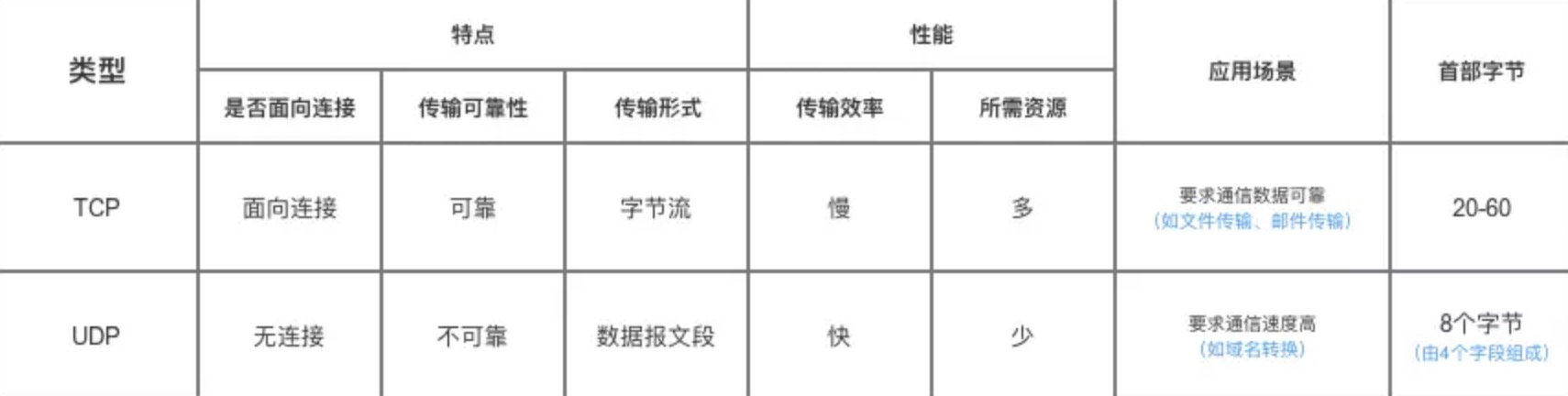
差别:
特点、传输形式、效率、资源、首部字节
TCP面向连接、是可靠的、以字节流传输,传输效率低,需要的资源多,首部20-60字节,文件传输,邮件传输,一对一
UDP无连接、不可靠的,以数据报文段传输,传输效率高,需要的资源少,首部8个字节,视频播放,一对一,一对多,多对一,多对多
TCP如何可靠
校验和:保持头部和数据的校验和
流量控制:TCP连接的每一方都有固定大小的缓冲空间,发送端只能发送接收端缓存区能接受的数据,实现:滑动窗口
拥塞控制:网络拥塞,减少数据的发送
ARQ协议(Automatic Repeat reQuest):决定数据发送的时机
超时重传:等待目的端接收的报文太长,重新发送
ARQ停止等待
每发完一个分组就停止发送,等待确认,一段时间后还没收到确认,就重新发送该分组
接收方如果收到重复的,丢弃该分组,但要发送确认
优点:简单
缺点:信道利用率低,等待时间长
连续ARQ协议
发送方维持一个发送窗口,窗口的分组可以连续发送出去,不需要等待对方确认,接收方采用累计确认,对按序到达的最后一个分组发送确认,表明正确接收到
优点: 利用率高,容易实现
缺点:不能反映接收方已经正确收到的所有分组的信息,如:发送方发送5条,但是丢失了3号,接收方只能确认1、2号,发送方只能把后三个都重传
流量控制(滑动窗口)
控制发送方的发送速率,保证接收方来得及接收,滑动窗口是实现
拥塞控制
发送方维护拥塞窗口和门限值,
算法:慢开始、拥塞避免、快重传和快恢复
慢开始:窗口1开始,正常就加倍
拥塞避免:到达门限值后,每次窗口加一
快重传:接收方每接受到一个失序的报文段就发出重复确认,发送方只要一连收到三个重复的确认就立即重传丢失的报文段,不等待重传计时器
快恢复:拥塞窗口降为一半,使用拥塞避免
重复确认:快重传、快恢复
超时重传:慢开始
三次握手
为什么
目的:确定双方能正确接收和发送信息
过程
- A发送syn标志的数据包
- B发送syn/ack的数据包
- A发送ack的数据包
syn建立连接、ack确认、fin结束、Sequence number(顺序号码)、Acknowledge number(确认号码)
- 建立连接,客户端发送请求连接报文段,顺序号为x,标志位SYN为1,客户端进入SYN_SEND状态,等待服务器确认
- 服务器收到SYN报文段,设置顺序号为y,ack number为x+1,标志位syn1,ack1,发给客户端,服务器进入SYN_RECV状态
- 客户端接收报文段,检查回复号是否正确,将序列号为x+1,ack number设置为y+1,标志位ack1,发送给服务器,发送完毕后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手

四次挥手
TCP是全双工的,每个方向都要关闭

A 和 B 打电话,通话即将结束后
A 说“我没啥要说的了”
B回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话
于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”
A 回答“知道了”,这样通话才算结束。
- 设置序列号x ,FIN报文段,A进入FIN_WAIT1
- 接收FIN,回复ACK = 序列号x+1,A进入FIN_WAIT2
- B向A发送FIN,请求关闭连接,B进入LAST_ACK
- 接收FIN,发送ACK,A进入TIME_WAIT,B收到ACK,关闭连接,A等待2MSL(报文最大生存时间)后没有收到回复,说明Server正常关闭,A也关闭
HTTP
请求方式
get、post、delete、put、options查看性能、head
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
|---|---|---|
| 2 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
信息格式
请求信息
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
数据响应信息
状态行、消息报头、空行和响应正文
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain响应头信息
| Allow | 服务器支持哪些请求方法(如GET、POST等)。 |
|---|---|
| Content-Encoding | 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。 |
| Content-Length | 表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据 |
| Content-Type | 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,HttpServletResponse,setContentType。 |
| Date | 当前的GMT时间。 |
| Expires | 应该在什么时候认为文档已经过期,从而不再缓存它? |
| Last-Modified | 文档的最后改动时间。 |
| Location | 表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。 |
| Refresh | 表示浏览器应该在多少时间之后刷新文档,以秒计。 |
| Server | 服务器名字。 |
| Set-Cookie | 设置和页面关联的Cookie。使用HttpServletResponse提供的专用方法addCookie |
| WWW-Authenticate | 客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader(“WWW-Authenticate”, “BASIC realm=\”executives\””)。 注意Servlet一般不进行这方面的处理,而是让Web服务器的专门机制来控制受密码保护页面的访问(例如.htaccess)。 |
状态码
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
|---|---|
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置”您所请求的资源无法找到”的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
长、短连接
http1.0中,每次http操作就建立一次连接,结束就中断,访问html中的其他web资源都需要重新建立http会话
http1.1起,默认使用长连接,保持连接特性
使用长连接的http协议,响应头会包含Connection:keep-alive,当一个网页打开后,客户端和服务器用于传输HTTP数据的TCP连接不会马上关闭,会维持一定的时间(由Apache等服务器软件设定),客户端再次访问这个服务器时,会继续使用这一条连接
cookie与session
http是无状态协议,用session解决这个问题,cookie中保存sessionid,session会在服务器保存一定时间
cookie被禁用: url将sessionID直接附加到URL路径后面
区别:
cookie存放在客户端,session存放在服务器,所以session安全性更高
HTTP1.0和1.1区别
长连接
- 1.0默认短连接,每次都要重新建立连接,http基于TCP/IP协议,每次都要三次握手,四次挥手,开销很大,
- 1.1持续连接有非流水方式和流水线方式,流水线能同时发送请求报文,非流水线要接受到响应才能继续发送
响应码
- 1.1新增状态响应码
缓存处理
- 1.1有更多的缓存策略
带宽优化及网络连接
- 1.1请求头引入range,允许只请求资源的某个部分,状态码206
HTTPS
https在传输数据前需要客户端和服务器进行TLS/SSL握手,握手过程将确立双方加密传输数据的密码信息,TLS/SSL使用非对称加密,对称加密以及hash
握手过程
加密通信前,需要建立连接和交换参数,过程为握手
A给出协议版本号、客户端生成的随机数,以及客户端支持的加密方法
B确认使用双方的加密方法,给A数字证书、服务器生成的随机数
A确认证书有效,生成一个新的随机数,使用证书中的公钥加密这个随机数发送给B
B使用私钥获取随机数
根据约定的加密方法,使用前面的3个随机数生成“对话密钥”,进行加密接下来的整个对话过程
注意点
- 生成密钥需要三个随机数
- 握手之后的对话使用对话密钥加密,服务器的公钥和密钥只用于“加密和解密”对话密钥
- 公钥放在服务器的数字证书中
HTTP和HTTPS的区别
端口
- http://开始,默认80端口,https://开始使用443端口
安全性和资源消耗
- HTTP直接运行在TCP上,传输的内容都是明文,客户端和服务器端都无法验证对方的身份
- HTTPS加了一层TLS/SSL,传输的内容进行加密,加密采用对称加密,获取加密密钥使用非对称加密,安全性较高
其他面试题
URL回车详细
- DNS解析
- 浏览器缓存、系统缓存、路由器缓存、根服务器、com顶级域名服务器、主域名服务器
- TCP连接、UDP协议
- HTTP请求,get等方法
- 服务器处理请求返回HTTP报文
- 浏览器渲染页面
TCP/IP层下涉及的协议
应用层:
- HTTP:www访问协议
- DNS协议:域名映射为IP地址
传输层:
- TCP协议:建立连接,提供可靠的数据传输,将HTTP请求报文分割成报文段
- UDP协议:
网络层协议:
- IP协议,路由选择
- ICMP协议,提供传输过程中的差错检测
网络接口层协议:
- ARP协议,将目的IP地址映射成物理MAC地址
URI和URL的区别
URI:统一资源标志符,唯一标识一个资源
URL:统一资源定位符,可以提供该资源的路径,是具体的URI,可以标识一个资源,而且告诉如何定位这个资源
URI像身份证号码,URL像家庭住址
IP地址
a类地址:0 0 - 127
b类地址:10 128 - 191
c类地址: 110 192 - 223
d类地址:1110 224 - 239
e类地址: 11110 240 - 255
数据结构
数组
特点:相同类型的元素组成,使用连续的内存来存储,通过元素的索引可以计算出元素的存储地址
提供随机访问并且容量有限
访问:O(0)
插入:O(n),最坏插入头部,需要移动所有元素
删除:O(n),最坏删除头部,需要移动所有元素链表
线性表,不会按线性顺序存储数据,使用不连续的内存空间存储数据
链表的插入和删除为O(1),查找访问为O(n)
- 不需要预先知道数据大小,充分利用计算机内存空间,实现动态内存管理
- 占用更多的空间,因为还存放其他节点的指针
- 不能像数组那样随机读取
单链表
循环链表
尾部指向头部
双向链表
包含两个指针,一个指向前节点,一个指向后节点,
双向循环链表
包含两个指针,一个指向前节点,一个指向后节点,尾部指向头部,头部指向尾部,形成环
树
红黑树
https://juejin.cn/post/6844903519632228365#comment
二叉查找树存在左倾右倾现象,退化成线性结构
- 节点是红色或者黑色
- 根节点是黑色的
- 每个叶子结点都是黑色的空节点
- 每个红色节点的两个子节点都是黑色的
- 任意节点到每个叶子的所有路径包含相同数目的黑色节点
图
图的存储
邻接矩阵存储
顶点i和顶点j有关系则 a[i][j] = 1, 如果是无向图则 a[j][i] 也= 1
优点,高效,缺点浪费空间
邻接表存储
链表存储顶点的相邻顶点
图的搜索
广度优先搜索
使用队列,标记有没有走过
Queue<String> queue = new LinkedList<String>();深度优先搜索
使用栈,标记有没有走过
Stack<Integer> st = new Stack<Integer>();设计模式
单例
锁实现
volatile static 两个if,synchronized
public class Singleton{
private volatile static Singleton singleton;
private Singleton() {}
public static Singleton getSingleton() {
if( singleton == null ) {
synchronized( Singleton.class ) {
if(singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}volatile,可见性是指多个线程访问同一个变量时,其中一个线程修改了该变量的值,其它线程能够立即看到修改的值。
能够禁止 JVM 重排序,:volatile 修饰的变量的读写指令不能和其前后的任何指令重排序,其前后的指令可能会被重排序。
class VolatileOrder {
int i = 0;
volatile boolean flag = false;
public void write() {
i = 1; // 步骤 1
flag = true; // 步骤 2
}
public String get() {
if (flag) { // 步骤 3
System.out.println("i = " + i); // 步骤 4
}
}
}静态内部类实现
当类被加载时,静态内部类的SingletonHolder没有被加载进内存,只有当调用getInstance方法,从而调用SingletonHolder时才会被加载,此时JVM能保证INSTANCE只被实例化一次
不仅具备延迟初始化的好处,而且线程安全
public class Singleton {
private Singleton() { }
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}JAVA
基础
语言特点
- 简单易学
- 面向对象
- 可移植性
- 可靠性
- 安全性
- 支持多线程
- 支持网络编程,并且方便
- 编译与解释并存
JDK和JRE
流程
.java ——> .class(字节码文件) ——-> 机器可自行的二进制机器码
javac jvm(运行 Java 字节码的虚拟机)
.class->机器码时
- JIT 属于运行时编译。
- 当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用
- 机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言
JDK(能够创建和编译程序)
编译器、工具(JavaDoc、jdb)
JRE(运行时环境)
- JVM
- 常用类库
JSP 转换为 Java servlet,需要使用 JDK 来编译 servlet
Oracle JDK 和 OpenJDK的对比
openJDK完全开源,Oracle JDK不完全开源
Oracle JDK在响应和JVM性能方面有更好的性能
Oracle JDK更稳定
编译与解释并存
编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;
解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。
先等翻译人员将全本的英文名著(也就是源码)都翻译成汉语,再去阅读,也可以让翻译人员翻译一段,你在旁边阅读一段,慢慢把书读
Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(*.class 文件),这种字节码必须由 Java 解释器来解释执行。因此,我们可以认为 Java 语言编译与解释并存。
泛型、类型擦除、通配符
泛型
JDK5的新特性,提供编译时类型安全检测机制,允许程序员在编译时检测到非法的类型
JAVA的泛型是伪泛型,在编译期间会擦除
通配符
常用的通配符为: T,E,K,V,?
- ? 表示不确定的 java 类型
- T (type) 表示具体的一个 java 类型
- K V (key value) 分别代表 java 键值中的 Key Value
- E (element) 代表 Element
==与equals
基本数据类型比较的是值,引用数据类型比较的是内存地址
hashCode和equals
hashCode获取int的哈希码,用于确定在哈希表中的索引位置,Object中的该方法是用对象的 内存地址 转换为整数后返回,能够提高性能。
==重写equals就要重写hashCode方法== ???
将对象存入HashMap中,会根据对象的hashcode值判断是否重复,如果没有重写这个方法,就永远不会相等,即使该对象拥有相同的属性
hashCode能计算对象的哈希码,equals在object中是 == 对比两对象的内存地址,String等对象中改写了hashCode、equals方法
当对象需要存入Set或者Map的key时,需要判断是否重复,如果原set中有1000个对象就需要遍历1000次,但是如果有hashCode,组成哈希表,当hashcode冲突时才调用equals方法,就能提高效率
基本数据类型
boolean、byte、char、short、int、long、float、double
包装类:Byte、Short、Integer、Long、Float、Double、Character、Boolean
Byte,Short,Integer,Long,Character,Boolean;
- 前面 4 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据
- Character 创建了数值在[0,127]范围的缓存数据
- Boolean 直接返回 True Or False。如果超出对应范围仍然会去创建新的对象
- 两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。
方法
传递
参数:是基本类型,则为拷贝,是引用类型则引用地址
重载和重写
重载:输入数据不同,做不同的处理
重写:子类覆盖父类的方法,输入数据一样,发生在运行期
浅拷贝和深拷贝
浅拷贝:
- 基本数据类型:值传递
- 引用数据类型:引用拷贝
深拷贝:
- 基本数据类型:值传递
- 引用数据类型:创建新的对象,复制其内容
==接口和抽象类==
相同点:
- 都不能被实例化
- 接口实现类和抽象类的子类都只有实现了接口或抽象方法后才能实例化
不同点:
- 接口只有定义,不能有实现,1.8中可以定义default方法体,
- 抽象类可以有定义和方法实现
- 接口关键字为implements,继承抽象类为extends,一个类可以实现多个接口,但一个类只能继承一个抽象类,接口可以间接多继承
- 接口强调特定功能的实现,抽象类强调所属的关系
- 接口变量默认为public static final,必须赋初值,不能被修改,所有成员方法都是public、abstract的
- 抽象类中成员变量默认default,可以在子类重新定义或重新赋值,抽象方法被abstract修饰,不能被private、static等修饰,没有花括号
抽象类不能创建实例,他只能被继承,从多个具体类抽离出来的父类
接口是说对行为的抽象,抽象类是具体类的抽象
抽象类是包含抽象方法的类,不能实例化
**抽象类**
1)抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public。
2)抽象类不能用来创建对象;
3)如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
**接口**
1. 可以包含变量、方法,变量指定为public static final,方法为public abstract(1.8前)
2. 接口可以多继承,一个类可以实现多个接口
3. 默认方法,1.8允许添加非抽象方法的实现,但是需要用default修饰,定义了default不
4. 静态方法,1.8允许使用static修饰一个方法,提供实现,接口静态方法只能通过接口调用关键字
public protect default private
外部包:public
在不同包下的子类所访问: protected
本包下的其他类: default
不想被任何一个外部的类所访问: private
final、static、this、super
修饰类、方法、变量
- final修饰的类不能被继承,final类中的所有方法隐式指定为final方法
- final修饰的方法不能重写,private方法隐式定义为final
- final修饰的基本数据类型,赋值后不能修改,修饰的是引用类型,初始化后,不能指向另一个对象
static
修饰成员变量和方法:static修饰的成员属于类,所有类的对象共享,其存放在方法区
静态代码块:在非静态代码块之前执行(静态代码块->非静态代码块->构造方法),该类不管创建多少对象,静态代码块只执行一次
- 可能在第一次new时执行一次(Class.forName创建对象也会执行),非静态代码块每new一次就执行一次
静态内部类(能够实现单例模式):
- 非静态内部类在编译完成后会隐含保存着一个引用,该引用指向创建它的外围类,但是静态内部类没有
- 意味着:它的创建不依赖外围类、它不能使用任何外围类的非static成员变量和方法
静态导包:import static可以导入某个类中指定的静态资源,不需要使用类名调用类中的静态变量,可以直接使用类中的静态成员变量和成员方法
import static java.lang.Math.*;
int max = max(1,2);this
transient
- 修饰变量,无法序列化(短暂的)
- 静态变量均无法被序列化
- 但是如果jvm中存在这个类,反序列化出来也会有值
- 实现serializable接口,所有序列化自动进行,如果是实现Externalizable接口,则没有任何东西可以自动序列化,需要在writeExternal指定需要序列化的变量
集合
简介
list:元素有序、可重复
set:元素无序、不可重复
map:key value键值对,key无序不可重复
list
arrayList:Object数组,适合频繁查找,线程不安全
Vector:object数组,线程安全
linkedList:双向链表(1.6前为循环)
区别:
线程安全
底层数据结构
插入和删除
快速访问
内存空间占用:ArrayList预留容量,LinkedList存放前驱后续,数据。
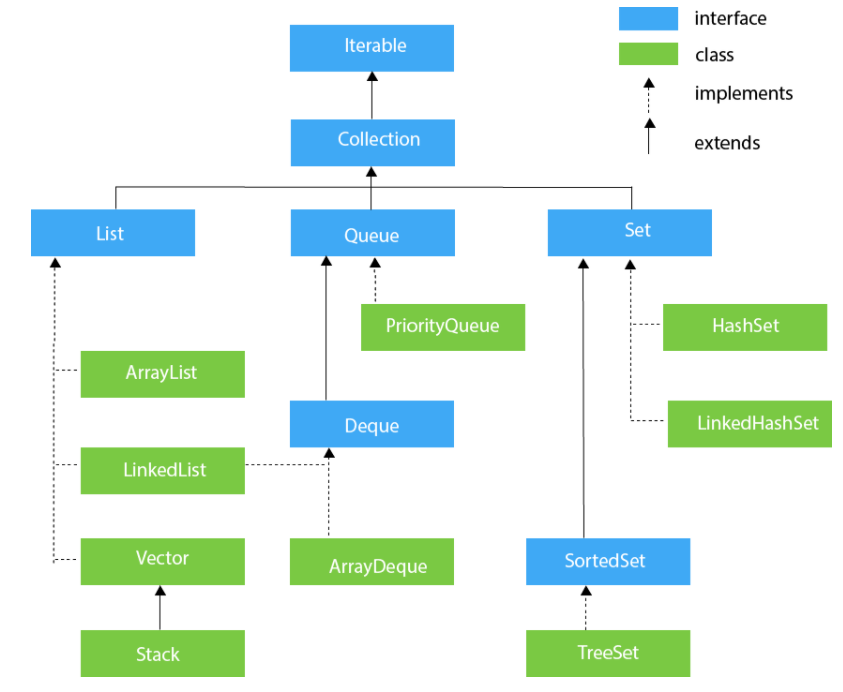
Set
HashSet: 无序,唯一,底层使用HashMap
LinkedHashSet:HashSet子类,内部通过LinkedHashMap实现
TreeSet:有序,唯一,红黑树(自平衡排序二叉树)
实战
@Data
@TableName("goods_operation_record")
public class GoodsOperationRecordEntity implements Serializable {
private static final long serialVersionUID = 1L;
/**
* id
*/
@TableId
private Integer id;
/**
* 物品id
*/
private Integer goodsId;
/**
* 用户id
*/
private Integer userId;
/**
* 创建时间
*/
@JsonFormat(timezone = "GMT+8", pattern = "yyyy-MM-dd HH:mm:ss")
private Date createTime;
/**
* 操作类型(0,是我的/1,领取)
*/
private Integer type;
@Override
public boolean equals(Object obj) {
if(!(obj instanceof GoodsOperationRecordEntity)) {
return false;
}
GoodsOperationRecordEntity b = (GoodsOperationRecordEntity)obj;
if(this.goodsId.equals(b.goodsId) && this.userId.equals(b.userId) ) {
return true;
}
return false;
}
@Override
public int hashCode() {
return goodsId.hashCode() ^ userId.hashCode();
}
}Set<RetrievedGoods> resSet = new LinkedHashSet<>();
list.stream().map(goodsOperationRecordEntity -> {
}).filter(item -> item != null)
.sorted(Comparator.comparing(RetrievedGoods::getId).reversed()).forEachOrdered(resSet::add);Map
HashMap:数组加链表,拉链法是为了解决哈希冲突,链表长度大于栈值(默认8)(数组长度小于64会先数组扩容),将链表转化为红黑树
LinkedHashMap: 继承HashMap,增加双向链表,保持键值对插入顺序
HashTable:线程安全?
TreeMap:红黑树
方法
map.contains("");
// 不存在则添加
map.putIfAbsent(i, i);
// 不存在默认返回
map.getOrDefault(42, "not found");
// 存在则修改
map.computeIfPresenet(3, (key, value) -> key + value);
// 不存在则修改
map.computeIfPresenet(3, key -> key+1 );
// 如果键名不存在则插入,否则对原键对应的值做合并操作并重新插入到map中
map.merge(9, "value", (value, newValue) -> value.concat(newValue) );
map.replaceAll((key, value) -> value*2);
遍历
// 增强for
foreach(Integer key : map.keySet()){
// key, map.get(key)
}
// 迭代器
Iterator<Map.Entry<Integer, String>> it = map.entrySet().iterator();
while(it.hasNext()) {
map.Entry<Integer, String> entry = it.next();
entry.getKey();
entry.getValue();
}
// 分别获取key,value
for(Integer obj:map.keySet()){
System.out.println("key:"+obj);
}
for(String obj:map.values()){
System.out.println("value:"+obj);
}
// entrySet,数据上万时,速度最快
Set<Map.Entry<Integer, String> entries = map.entrySet();
for(Map.Entry entry: entries) {
entry.getKey();
entry.getValue();
}HashMap
底层拉链法,数组加链表,当16最大容量 * 0.75负载因子 > 12,则扩容 16 * 2 = 32(位运算),链表长度大于等于8则转换为红黑树,节点个数小于6退化为链表
线程不安全:
- 线程A、B要put,A找好位置准备添加时,B先添加了,A就会覆盖记录
- 扩容成环,会死循环
解决:
ConcurrentHashMap,采用分段锁,将数据分成多段存储,访问其中一段加锁时,其他的可以访问
面向对象
堆中:存储对象
栈中:存储局部变量和方法调用
类和对象
面向对象和面向过程
面向过程:
- 性能高
面向对象:
优点:
- 易维护、易复用、易扩展
缺点
- 类调用需要实例化,开销大,耗资源
- Java 性能差的主要原因并不是因为它是面向对象语言,而是 Java 是半编译语言,最终的执行代码并不是可以直接被 CPU 执行的二进制机械码
反射
框架的灵魂,能够让我们在运行时分析类以及执行类中方法的能力, 可以让代码更加灵活
缺点:
- 安全问题,比如无视泛型参数的安全检查
- 性能稍差
常用方法

注解
@Target 描述该注解使用范围
@Rentention 描述声明周期(SOURCE<CLASS<RUNTIME)
@Document 说明注解包含在javadoc中
@Inherited 可以继承该注解获取class对象
// 1
Class class = Person.class;
// 2
Class class = person.getClass();
// 3
Class class = Class.forName("domo.Student");
// 4.通过类加载器
class clazz = ClassLoader.LoadClass("cn.javaguide.TargetObject");反射调用普通方法
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InstantiationException, InvocationTargetException, NoSuchFieldException {
/**
* 获取TargetObject类的Class对象并且创建TargetObject类实例
*/
Class<?> tagetClass = Class.forName("cn.javaguide.TargetObject");
TargetObject targetObject = (TargetObject) tagetClass.newInstance();
/**
* 获取所有类中所有定义的方法
*/
Method[] methods = tagetClass.getDeclaredMethods();
for (Method method : methods) {
System.out.println(method.getName());
}
/**
* 获取指定方法并调用
*/
Method publicMethod = tagetClass.getDeclaredMethod("publicMethod",
String.class);
publicMethod.invoke(targetObject, "JavaGuide");
/**
* 获取指定参数并对参数进行修改
*/
Field field = tagetClass.getDeclaredField("value");
//为了对类中的参数进行修改我们取消安全检查
field.setAccessible(true);
field.set(targetObject, "JavaGuide");
/**
* 调用 private 方法
*/
Method privateMethod = tagetClass.getDeclaredMethod("privateMethod");
//为了调用private方法我们取消安全检查
privateMethod.setAccessible(true);
privateMethod.invoke(targetObject);
}
}
实例
@TableMing("db_student")
Class Student{
@FieldMing(columnName = "db_id", type = "int", length = 10)
private int id;
@FieldMing(columnName = "db_age", type = "int", length = 10)
private int age;
3 @FieldMing(columnName = "db_name", type = "varchar", length = 10)
private String name;
/*get set*/
}
@TableMing("db_student")
class student2{}
//类名注解
@Target(ElementType.Type) //作用在type上
@Retnetion(RetentionPolicy.RUNTIME) //在runtime可以获取
@interface TableMing{
String value();
}
//属性的注解
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@interface FieldMing{
String columnName(); //类名
String type(); //参数类型
int length();
}
public void test(){
Class c1 = Class.forName("com.ming.reflection.Student");
//通过反射获取注解
Annotation[] annotation = c1.getAnnotations();
for(Annotation annotation : annotations){
sout(annotation);
}
//获取注解的value的值
TableMing TableMing = (TableMing)c1.getAnnotation(TableMing.class);
String value = tableMing.value();
sout(value);
//获取类指定的注解
Field f = c1.getDeclaredFiled("name");
FieldMing annotation = f.getAnnotation(FieldMing.class);
sout(annotaion.columnName());
}日期
System.nanoTime();
TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));IO流
序列化:将数据结构或对象转为二进制字节流
反序列化:序列化生成的二进制流转为数据结构或者对象
序列化使用:对象保存文件,网络传输
并发编程
Offer来了
概念
进程和线程
进程是资源调度的基本单位,线程是任务的调度执行的基本单位
进程有自己独立的数据空间,进程之间切换开销大
线程使用进程的资源,也有自己运行栈和程序计算器,切换开销较小,是轻量级进程
一个进程包括由操作系统分配的内存空间,包含一个或多个线程。一个线程不能独立的存在,它必须是进程的一部分。一个进程一直运行,直到所有的非守护线程都结束运行后才能结束
工作:在修改同一数据库数据时,线程1先执行update,线程4再执行,但是线程4先执行结束了,猜测可能是被锁住了
创建线程
Thread
继承Thread,重写run()方法,创建、执行start()方法
start方法是一个native方法,通过在操作系统上启动一个新线程,并最终执行run方法来启动一个线程
Runnable接口
实现Runnable接口,实现run()方法
new Thread( new MyThread() ).start(); 将实现类实例给Thread,Thread的run方法在执行时就会调用target.run方法并执行该线程具体的实现逻辑
public void run() {
if(target != null) target.run();
}callable和Futrue/ExecutorService
task类实现callable的call方法,通过task类创建futureTask,通过futureTask创建Thread并start,能够通过futureTask获取结果
class MyCallable implements Callable<String> {
public String call() throws Exception {
return longTimeCalculation();
}
}
// 1.
ExecutorService executor = Executors.newFixedThreadPool(4);
// 定义任务:
Callable<String> task = new MyCallable();
// 提交任务并获得Future:
Future<String> future = executor.submit(task);
// 从Future获取异步执行返回的结果:
String result = future.get(); // 可能阻塞
// 2.
FutureTask<String> futureTask = new FutureTask<>(new MyCallable());
new Thread(futureTask).start();
String result = futureTask.get();区别
- 使用Runnable(run)和callable(call)实现接口还可以继承别的类
- 通过callable和future能够获取结果
- 使用继承 Thread 类的方式创建多线程时,编写简单,如果需要访问当前线程,则无需使用 Thread.currentThread() 方法,直接使用 this 即可获得当前线程。
线程池方式
线程每次创建和销毁都是消费资源的,使用线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
// 在for中
threadPool.execute(new Runnable() {
public void run() {}
})线程池工作原理
用于管理线程组及其运行状态,以便更好的利用CPU资源
线程复用、线程资源管理、控制操作系统的最大并发数,保证系统高效且安全的运行
原理:JVM创建一定数量的的线程任务放入队列中,在线程创建后启动这些任务,如果线程数量超过了最大线程数量(用户设置的线程池大小),则超出数量的线程排队等候,在有任务执行完毕后,线程池调度器会发现有可用的线程,进而再次从队列中取出任务并执行。
线程复用
Thread类的run方法是执行调用Runnable对象的run方法,通过继承Thread类,在start方法中不断循环调用传进来的Runnable对象,程序不断执行run方法
将Runnable对象放入队列,线程池从里面取
核心组件和核心类
线程池管理器:创建并管理线程池
工作线程:线程池中执行具体任务的线程
任务接口:工作线程的调度和执行策略
任务队列:存放待处理的任务

ThreadPoolExecutor构造函数的具体参数:
核心数量,最大数量,超过核心线程数时的存活时间,时间单位,未执行的任务队列,创建线程的工厂,拒绝策略

工作流程
创建线程池时,向系统申请一个用于执行线程队列和管理线程池的线程资源,使用execute添加任务时
优先级:核心线程—》任务队列—》最大线程-》拒绝策略
初始化后不直接创建线程,只有请求时才启动
任务进来,运行的线程数少于corePoolSize,立即创建线程并执行该任务
大于corePoolSize,放入阻塞队列中
阻塞队列满了,运行中的线程数少于最大线程数时,创建非核心线程立即执行任务
阻塞队列满了,运行中的线程数大于等于最大线程数时,线程池会拒绝执行任务并抛出RejectExecutionException异常
执行完毕后,任务从线程池队列移除,从队列中取下一个线程任务执行
线程处在空闲状态的时间超过keepAliveTime时,正在运行的线程数超过corePoolSize,该线程将会被认定为空闲线程并停止,线程池收缩到核心线程数大小。
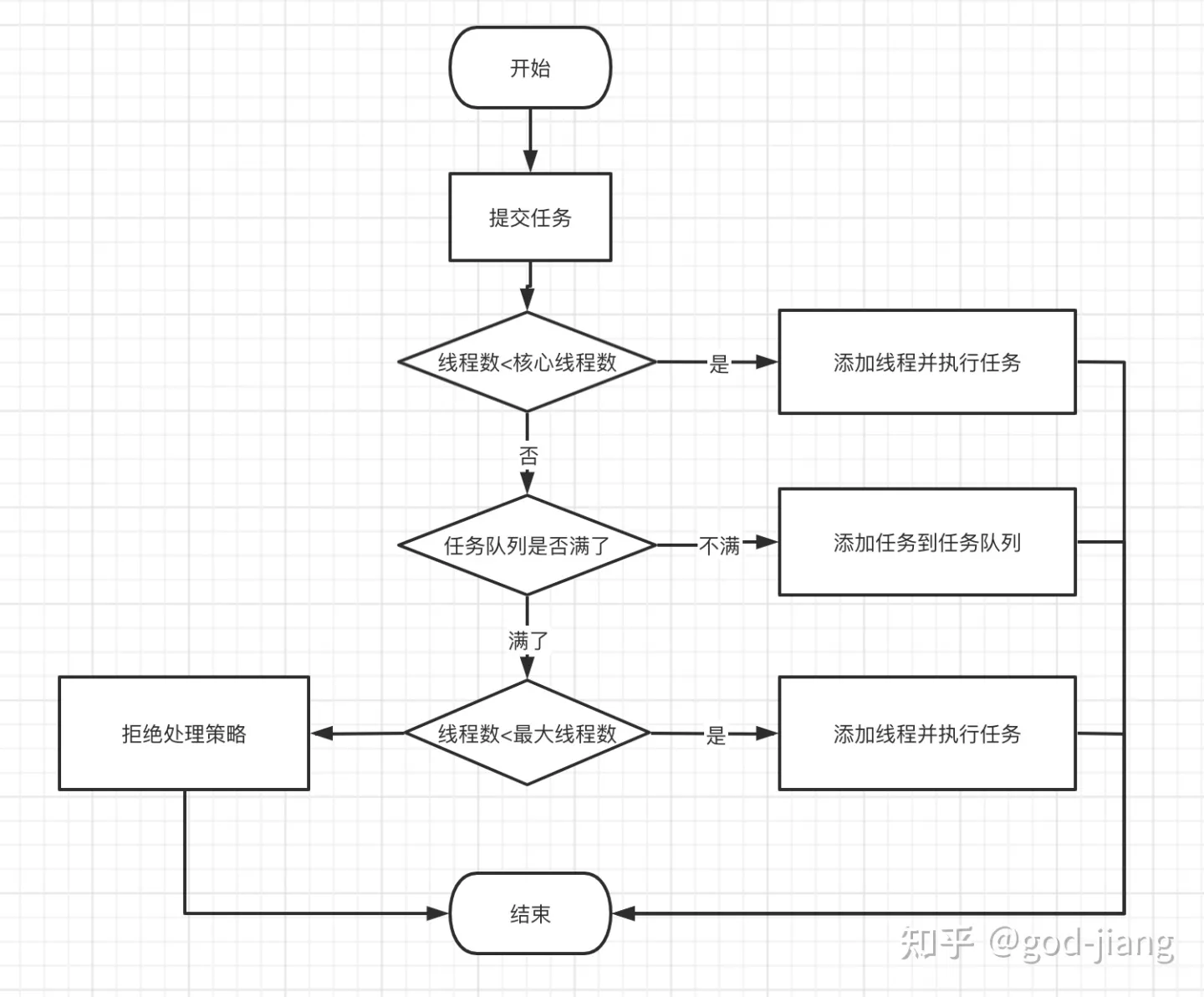
拒绝策略
核心线程数被用完且阻塞队列已满,线程池没有足够的线程资源执行新任务,线程池通过拒绝策略处理新添加的线程任务
JDK默认拒绝策略:AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy,继承ThreadPoolExecutor实现自定义
AbortPolicy
AbortPolicy直接抛出异常,阻止线程正常运行
CallerRunsPolicy
如果被丢弃的线程任务未关闭,则执行该线程任务
DiscardOldestPolicy
移除线程队列中最早的一个线程任务,并尝试提交当前任务
DiscardPolicy
丢弃当前的线程任务而不做任何处理。
如果系统允许在资源不足的情况下丢弃部分任务,则这将是保障系统安全、稳定的一种很好的方案
自定义
RejectedExecutionHandler接口来实现拒绝策略,并捕获异常来实现自定义拒绝策略
常用的线程池
Executor接口中定义了execute()用于执行一个线程任务,通过ExecutorService实现Executor接口执行具体的线程操作

ThreadPoolExecutor
初始化后不直接创建线程,只有请求时才启动
/*
核心线程数: 一直存在
最大线程数量
存活时间: 线程空闲一段时间就释放,最少线程数为核心线程数
超时时间单位
阻塞队列: 如果任务很多,就会放入队列中,有线程空闲就取出
线程创建工厂:默认
拒绝策略: 队列满了的措施
*/
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5,
200,
10,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(100000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
// 继承thread 或者 将实现run的runnable接口的类放入new Thread()
executor.execute(() -> {
System.out.printf("ddd");
});
// 实现call方法
Callable<String> task = new MyCallable();
Future<String> future = executor.submit(task);ThreadPoolTaskExecutor
spring对threadPoolExector的封装,可以指定名称
ThreadPoolTaskExecutor实现了InitializingBean, DisposableBean ,xxaware等,具有spring特性
需要手动调initialize才会创建ThreadPoolExecutor,如果@Bean 就不需手动,会自动InitializingBean的afterPropertiesSet来调initialize
配置
# 核心线程池数
spring.task.execution.pool.core-size=5
# 最大线程池数
spring.task.execution.pool.max-size=10
# 任务队列的容量
spring.task.execution.pool.queue-capacity=5
# 非核心线程的存活时间
spring.task.execution.pool.keep-alive=60
# 线程池的前缀名称
spring.task.execution.thread-name-prefix=god-jiang-task-或者类配置
@Configuration
public class AsyncScheduledTaskConfig {
@Value("${spring.task.execution.pool.core-size}")
private int corePoolSize;
@Value("${spring.task.execution.pool.max-size}")
private int maxPoolSize;
@Value("${spring.task.execution.pool.queue-capacity}")
private int queueCapacity;
@Value("${spring.task.execution.thread-name-prefix}")
private String namePrefix;
@Value("${spring.task.execution.pool.keep-alive}")
private int keepAliveSeconds;
@Bean
public Executor myAsync() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//最大线程数
executor.setMaxPoolSize(maxPoolSize);
//核心线程数
executor.setCorePoolSize(corePoolSize);
//任务队列的大小
executor.setQueueCapacity(queueCapacity);
//线程前缀名
executor.setThreadNamePrefix(namePrefix);
//线程存活时间
executor.setKeepAliveSeconds(keepAliveSeconds);
/**
* 拒绝处理策略
* CallerRunsPolicy():交由调用方线程运行,比如 main 线程。
* AbortPolicy():直接抛出异常。
* DiscardPolicy():直接丢弃。
* DiscardOldestPolicy():丢弃队列中最老的任务。
*/
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
//线程初始化
executor.initialize();
return executor;
}
}使用
@Async("myAsync")ThreadPoolTaskScheduler
结构上与ThreadPoolTaskExecutor多了一个TaskScheduler,而TaskScheduler是专门用于调度任务的类,这也从根本上区分了两者的用途
newCachedThreadPool
创建新线程时如果有可重用的线程,则重用它们,否则重新创建一个新的线程并将其添加到线程池中
对于执行时间很短的任务而言,newCachedThreadPool线程池能很大程度地重用线程进而提高系统的性能
在线程池的keepAliveTime时间超过默认的60秒后,该线程会被终止并从缓存中移除
因此在没有线程任务运行时,newCachedThreadPool将不会占用系统的线程资源。
ExecutorService cacheThreadPool = Executors.newCachedThreadPool();newFixedThreadPool
创建一个固定线程数量的线程池,并将线程资源存放在队列中循环使用。
若处于活动状态的线程数量大于等于核心线程池的数量,则新提交的任务将在阻塞队列中排队,直到有可用的线程资源
newScheduledThreadPool
创建了一个可定时调度的线程池,可设置在给定的延迟时间后执行或者定期执行某个线程任务
ScheduleExecutorService scheduleExecutorPool = Executors.newScheduledThreadPool(3);
// 延迟3s执行线程
scheduledThreadPool.schedule(new Runnable() {}, 3, TimeUnit.SECONDS);
// 延迟1s,每3秒执行一次
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {}, 1, 3, TimeUnit.SECONDS);newSingleThreadExecutor
保证永远有且只有一个可用的线程,发生异常时,启动一个新的线程来代替继续执行
ExecutorService singleThread = Executors.newSingleThreadExecutor();newWorkStealingPool
创建持有足够线程的线程池来达到快速运算的目的,在内部通过使用多个队列来减少各个线程调度产生的竞争
JDK根据当前线程的运行需求向操作系统申请足够的线程,以保障线程的快速执行,提高并发计算的效率,省去用户根据CPU资源估算并行度的过程。
CompletableFuture
创建 applyAsync | runAsync
ExecutorService executor;
CompletableFuture<Void> future =
// 1.无结果
CompletableFuture.runAsync(() -> { }, executor);
// 2.有结果
CompletableFuture.supplyAsync(() -> { }, executor);
// 3.new CompletableFuture<Integer>();
// thread 中 future.complete(100);
// future.whenComplete( (res, exception) -> { } );回调 whenComplete
// 方法完成后的感知
// future.[] ...
whenComplete( (res, exception) -> {} ); // 急,执行完后当前任务的线程 继续 执行 whenComplete 的任务
whenCompleteAsync( (res, exception) -> {} ,executor); // 不急,把CompleteAsyn的任务继续提交给线程池
exceptionally( throwable -> {return 10;} ); // 直接拿到异常
// 方法执行后的处理
handle( (res, throwable) -> { return res == null || throwable == null} );
// 阻塞获取结果
future.get();whenComplete与whenCompleteAsync的区别
来自:https://blog.csdn.net/leon_wzm/article/details/80560081
whenComplete:线程A执行了future.complete,则A执行whenComplete,但是如果A执行完,whenComplete还没执行到,则最先看到whenComplete的线程执行
whenCompleteAsync:让线程池执行
串行化 then
A -> B
thenRun: 不能获取返回值,A完成,就执行B线程
thenAccept: 能获取A返回值,无返回结果
thenApply: 能获取A线程返回值 且 返回B线程返回值
# ...Async则放入线程池中处理组合 runAfterBoth
A and B
# future1.[]
# 两个都运行完
.thenCombine( future2, (res1, res2) -> { return 1; } ): 获取结果,修改返回值
.thenAcceptBoth( future2, (res1, res2) -> { } ): 获取结果,无返回值
.runAfterBoth( futrue2, () -> { } ): 运行完后,运行该任务
# 最先运行完
.applyToEither( future2, (res) -> { return 1; } ): 获取结果,修改返回值
.acceptEither( future2, (res) -> { } ): 只能获取结果
.runAfterEither( future2, { } ): 运行完后,运行该任务
# async ,加入线程池运行多任务 allOf | anyOf
// allOf & anyOf
CompleteableFuture<Void> allof = CompletableFuture.allOf(f1, f2, f3);
allof.get(); // 等待都运行完
f1.get(); // 再获取
anyof.get(); // 其中一个运行完,第一个运行完的值线程生命周期
新建:创建线程对象后,保持新建状态直到start()该线程
就绪:start()后就绪,等待JVM线程调度
运行:获取到CPU资源,执行run()
阻塞
- 等待阻塞:wait()
- 同步阻塞:获取synchronized同步锁失败
- 其他阻塞:sleep()或join()、发出io请求,结束后进入就绪状态
死亡
- run方法或call方法执行完成
- 运行中的线程抛出一个Error或未捕获的Exception,线程异常退出
- stop方法手动结束(瞬间释放线程占用的同步对象锁,导致锁混乱和死锁,不推荐使用)

线程的基本方法
wait、sleep、join、yield、notify、notifyAll、setDaemon方法
各方法对线程状态的:

wait:进入waiting状态,等待其他线程通知或被中断后返回,会释放锁
sleep:线程休眠,不会释放锁,进入timed-waiting状态
yield:让出CPU执行时间片,重新竞争
interrupt:向线程发行一个终止通知信号,会影响该线程内部的一个中断标识位,这个线程本身并不会因为调用了interrupt方法而改变状态(阻塞、终止等)
- 调用interrupt方法并不会中断一个正在运行的线程,只是改变了中断标识位
- sleep状态使线程处于timed-wating状态,调用interrupt会抛出interuptedException,提前结束timed-wating状态
- 抛出InterruptedException的方法如Thread.sleep(long mills),在抛出异常前都会清除中断标识位,所以在抛出异常后调用isInterrupted方法将会返回false。
- 中断状态是线程固有的一个标识位,可以通过此标识位安全终止线程比如,在想终止一个线程时,可以先调用该线程的interrupt方法,然后在线程的run方法中根据该线程isInterrupted方法的返回状态值安全终止线程。
join:当前线程转为阻塞状态,等到另一个线程结束,当前线程再由阻塞状态转为就绪状态,等待获取CPU的使用权
notify/all:用于唤醒在此对象监视器上等待的一个线程,如果所有线程都在此对象上等待,则会选择唤醒其中一个线程,选择是任意的
通常调用其中一个对象的wait方法在对象的监视器上等待,直到当前线程放弃此对象上的锁定,才能继续执行被唤醒的线程
setDaemon:
定义一个守护线程,也叫作“服务线程”,为用户线程提供公共服务,在没有用户线程可服务时会自动离开,垃圾回收线程就是一个经典的守护线程
依赖于JVM,在JVM中的所有线程都是守护线程时,JVM就可以退出了
sleep和wait
- sleep方法属于Thread类,wait方法则属于Object类
- sleep方法暂停执行指定的时间,让出CPU给其他线程,但其监控状态依然保持,在指定的时间过后又会自动恢复运行状态
- 调用sleep方法的过程中,线程不会释放对象锁。
- 在调用wait方法时,线程会放弃对象锁,进入等待此对象的等待锁池,只有针对此对象调用notify方法后,该线程才能进入对象锁池准备获取对象锁,并进入运行状态
start与run
- start方法用于启动线程,真正实现了多线程运行
- 调用Thread类的start方法启动一个线程时,此线程处于就绪状态,并没有运行
- run方法也叫作线程体,包含了要执行的线程的逻辑代码,在调用run方法后,线程就进入运行状态,开始运行run方法中的代码。在run方法运行结束后,该线程终止,CPU再调度其他线程。
结束进程
正常运行结束
使用退出标志
// extends Thread
// volatile用于使exit线程同步安全
public volatile boolean exit = false;
public void run() {
while(!exit) {}
}interrupt
线程处于阻塞状态
在使用了sleep、调用锁的wait或者调用socket的receiver、accept等方法时,会使线程处于阻塞状态,调用线程的interrupt方法时,会抛出InterruptException异常
通过代码捕获该异常,然后通过break跳出状态检测循环,可以有机会结束这个线程的执行
while(isInterrupted()) {
try {} catch( InterruptedException e ) {
break;
}
}线程未处于阻塞状态
线程中使用isInterrupted方法判断线程的中断标志来退出循环,在调用interrupt方法时,中断标志会被设置为true,并不能立刻退出线程,而是执行线程终止前的资源释放操作,等待资源释放完毕后退出该线程。

stop
该线程的子线程会抛出ThreadDeatherror错误,并且释放子线程持有的所有锁,被保护的数据就可能出现不一致的情况
共享
ThreadLocal
每个线程本地专属变量
private static final ThreadLocal<SimpleDateFormat> formatter =
ThreadLocal.withInitial(
() -> new SimpleDateFormat("yyyyMMdd HHmm")
);
formatter.set(new SimpleDateFormat());
formatter.get().toPattern();Thread中存在threadLocals和inheritableThreadLocals变量,默认为null,只有调用ThreadLocal的set或者get才创建
ThreadLocalMap以ThreadLocal作为key
// threadLocal
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}内存泄露
ThradLocalMap 的 key为 ThreadLocal 的弱引用,而value是强引用
如果ThreadLocal没有在外部强引用时,垃圾回收会清理key,value留下,无法回收,最好手动调用remove()方法
- 如果
new ThreadLocal<>().set(s);gc后将会清空key,而value没被回收,内存泄露 - 如果
ThreadLocal<Object> threadLocal = new ThreadLocal<>()将会有强引用,key不为null
锁与JUC
保障多并发线程情况下数据的一致性
乐观锁、悲观锁
公平性:公平锁、非公平锁
共享资源:共享锁、独享锁
状态:偏向锁、轻量级锁、重量级锁
乐观锁
每次读取时都认为别人不会修改该数据,更新时判断期间是否有修改,写前取出版本号后加锁
通过CAS(compare And Swap对比和交换)实现,原子更新操作,操作数据前比较当前值和传入的值是否一样,一样则更新,不一样不执行,返回失败
悲观锁
在每次读取都认为别人会修改数据,所以每次都加锁
通过==AQS==(Abstract Queued Synchronized),依赖他的:synchronized、ReentrantLock、Semaphore、CountDownLatch,该框架下的锁会先尝试以CAS乐观锁去获取锁,获取不到则转化为悲观锁
自旋锁
如果锁很快就能释放,那么那些等待锁的线程就不需要在内核态和用户态之间的切换进入阻塞、挂起状态,只需要等一等(自旋),在释放锁后立即就能获取锁,避免了用户再内核状态切换上的时间消耗
自旋时会占有CPU,如果获取不到锁就会一直浪费CPU,所以需要设定一个自旋等待的最大时间,自旋超过时间后,就退出自旋并释放锁
优缺点
优点:
- 减少CPU上下文的切换,自旋CPU耗时明显少于线程阻塞、挂起、再唤起时两次CPU上下文切换所用的时间,占用锁时间短或竞争不激烈来说性能大幅提升
缺点:
- 锁等待时间长或竞争激烈时,长时间自旋引起CPU浪费
时间阈值
JDK 1.5为固定的时间
JDK 1.6引入了适应性自旋锁。由上一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的,可基本认为一个线程上下文切换的时间是就一个最佳时间
CAS
对比并交换,乐观
CAS操作包含3个操作数,内存位置V、预期原值A、新值B,如果内存位置的值与预期原值相匹配,则将该位置的值修改为新值
我认为位置V应该为预期值A,如果包含,则B放入该位置,否则不更改,只需要告诉现在的值
AQS
AbstractQueuedSynchronizer,抽象队列同步器,抽象类,用来构建锁和同步器
ReentrantLock、Semaphore、ReentrantReadWriteLock、SynchronousQueue、FutureTask
原理:线程要的资源空闲,则线程有效,将共享资源锁定,请求该资源的其他线程就要阻塞等待锁。
实现:CLH,将暂时获取不到锁的线程加入队列中
CLH队列是虚拟的双向队列(仅存在节点间关联关系),AQS将请求共享资源的线程封装成一个CLH锁的一个节点实现锁的分配
CountDownLatch
让 x 个线程阻塞在一个地方,等待所有线程都执行完毕,放学都走了才关门
方法:
new CountDownLatch(300)
await( )
countDown( )
用法:
- 线程开始前等待n个线程执行完毕,都执行完再执行某个服务(await的线程)
- 多个线程开始执行任务的最大并行性,都准备好了开始执行
不足:
- 一次性
CyclicBarrier 循环栅栏
放学寝室的必须一起走
比CountDownLatch更复杂强大,应用场景类似,
CountDownLatch基于AQS,CycliBarrier基于ReentrantLock(也属于AQS)
await,到达屏障,线程都到达才继续执行,可以await重复使用
Synchronized
为Java对象、方法、代码块提供线程安全的操作
synchronized属于独占式的悲观锁,同时属于可重入锁(同一个线程重复请求自己持有的锁对象,可以请求成功),非公平锁。
作用范围
- 成员变量和2
A线程依赖B线程的资源,B线程依赖A线程的资源,可能出现死锁
实现原理
ContentionList、EntryList、WaitSet、OnDeck、Owner、!Owner
ContentionList:锁竞争队列,所有请求锁的线程都被放在竞争队列中
EntryList:竞争候选列表,在Contention List中有资格成为候选者来竞争锁资源的线程被移动到了Entry List中
WaitSet:等待集合,调用wait方法后被阻塞的线程将被放在WaitSet中
OnDeck:竞争候选者,在同一时刻最多只有一个线程在竞争锁资源
Owner:竞争到锁资源的线程被称为Owner状态线程。
!Owner:在Owner线程释放锁后的状态
synchronized在收到新的锁请求时首先自旋,如果通过自旋也没有获取锁资源,则将被放入锁竞争队列ContentionList中
为了防止锁竞争时锁竞争队列被大量的并发线程进行CAS访问影响性能,Owner线程在释放锁资源时间ContentionList的部分线程移动到EntryList,指定EntryList某个线程为OnDesk线程,没有直接把锁传递给OnDesk线程,而是让OnDeck线程重新竞争锁(自旋的线程也可以竞争),“竞争切换”,牺牲公平性,提高性能
Owner线程被wait阻塞后,被转移到WaitSet中,直到被Notify/all唤醒,再次进入EntryList中,ContentionList、EntryList、WaitSet线程均为阻塞状态,由操作系统完成
先尝试自旋获取锁(直接抢占OnDeck线程的锁资源)(对于已经进入队列是不公平的,是非公平锁),获取不到就进入ContentionList
重量级操作,需要调用操作系统接口,性能低,加锁时间可能超过业务代码的时间
JDK1.6优化,引入适应自旋、锁消除、锁粗化、轻量级锁及偏向锁等以提高锁的效率
锁膨胀:锁从偏向锁升级到轻量锁、在升级到重量级锁,1.6默认开启偏向锁和轻量级锁
ReentrantLock
继承Lock接口,是可重入锁(该锁支持一个线程对同一个资源进行多次加锁操作)
支持公平锁和非公平锁实现
不仅提供synchronized对锁的操作功能,还提供可响应中断锁、可轮训锁请求、定时锁避免死锁
public static ReentrantLock lock = new ReentrantLock();
lock.lock(); // 可以多次
lock.unlock(); // 响应多次,如果释放多于获取锁的次数抛出IllegalMonitorStateException异常==避免死锁-响应中断==
可以中断对锁的请求
ReentrantLock lock = new ReentrantLock();
// 未被中断则获取
lock.lockInteruptibly();
// 持有锁则释放
if(lock.isHeldByCurrentThread()) {
lock.unlock();
}
// while System.currnetTimeMillis() - time >= 3000
thread.interrupt(); // 中断一个线程避免死锁-可轮询锁
boolean tryLock()获取
避免死锁-定时锁
boolean tryLock(time, unit) thrrowsInterruptedException获取,
给定时间内获取到了锁,且线程未被中断,获取锁并返回true
如果时间内获取不到锁,禁用当前线程,直到
- 获取到锁并返回true
- 进入方法时设置了线程的中断状态,或者在获取锁时被中断,则抛出InterruptedException,清除当前线程的已中断短肽
- 超过时间,返回false,如果时间为0则不等待
Lock接口的方法
void lock()
boolean tryLock()
tryLock(timeout, unit)
void unlock():如果不持有锁则报错
Condition newCondition():等待通知组件
getHoldCount():查询当前线程保持锁的次数(lock的次数)
getQueryLength(): 返回等待此锁的线程估计数
hasQueuedThreads():查询是否有线程等待该锁
isFair():查询是否有线程等待该锁
isHeldByCurrentThread():查询当前线程是否持有该锁
isLock():判断此锁是否被线程占用
lockInterruptibly():如果当前线程未被中断,则获取该锁
synchronized与lock
synchronized是jvm层面,lock是java接口
synchronized不能获取锁状态,lock可以
lock具有读写锁提高性能
公平锁与非公平锁
公平锁指锁的分配和竞争机制是公平的,即遵循先到先得原则。
非公平锁指JVM遵循随机、就近原则分配锁的机制。
ReentrantLock(boolean fair)中传递不同的参数来定义不同类型的锁,默认的实现是非公平锁
tryLock、lock和lockInterruptibly
- tryLock若有可用锁,则获取该锁并返回true,否则返回false,不会有延迟或等待
- tryLock(long timeout, TimeUnit unit)可以增加时间限制,如果超过了指定的时间还没获得锁,则返回false
- lock若有可用锁,则获取该锁并返回true,否则会一直等待直到获取可用锁。
- 在锁中断时lockInterruptibly会抛出异常,lock不会。
synchronized和ReentrantLock
相同点
都用于控制多线程对共享对象的访问
都是可重入锁。
都保证了可见性和互斥性
不同点
- ReentrantLock显式获取和释放锁;synchronized隐式获取和释放锁。为了避免程序出现异常而无法正常释放锁,在使用ReentrantLock时必须在finally控制块中进行解锁操作。
- ReentrantLock可响应中断、可轮回,为处理锁提供了更多的灵活性。
- ReentrantLock是API级别的,synchronized是JVM级别的
- ReentrantLock通过Condition可以绑定多个条件
- 二者的底层实现不一样:synchronized是同步阻塞,采用的是悲观并发策略;Lock是同步非阻塞,采用的是乐观并发策略。
- Lock是一个接口,而synchronized是Java中的关键字,synchronized是由内置的语言实现的
- 通过Lock可以知道有没有成功获取锁,通过synchronized却无法做到
- Lock可以通过分别定义读写锁提高多个线程读操作的效率
Semaphore
一种基于计数的信号量,设定一个阈值,多个线程竞争获取信号,获取到信号则开启业务逻辑,执行完后释放信号,新加入的线程没有信号后被阻塞,直到有信号被释放
Semaphore semp = new Semaphore(5);
try {
semp.acquire();
try{
} catch(Exception e) {
} finally {
semp.release();
}
} catch(InterruptedException e) {
}acquire方法和release方法来获取和释放许可信号资源
Semaphone.acquire方法默认和ReentrantLock. lockInterruptibly方法的效果一样,为可响应中断锁,也就是说在等待许可信号资源的过程中可以被Thread.interrupt方法中断而取消对许可信号的申请
可以实现响应中断、可轮训、定时锁、公平锁和非公平锁
Semaphore也可以用于实现一些对象池、资源池的构建
比如静态全局对象池、数据库连接池等
此外,我们也可以创建计数为1的Semaphore,将其作为一种互斥锁的机制(也叫二元信号量,表示两种互斥状态),同一时刻只能有一个线程获取该锁。
AtomicInteger
JVM为此类原子操作提供了一些原子操作同步类,使得同步操作(线程安全操作)更加方便、高效
synchronized和ReentrantLock均属于重量级锁
AtomicInteger、AtomicBoolean、AtomicInteger、AtomicLong、AtomicReference
getAndIncrement() 自增
可重入锁
递归锁,统一线程中,在外层函数获取到该锁后,内层的递归函数依然可以继续获取该锁,如ReentryLock和synchronized都是
公平锁与非公平锁
公平:分配锁分配给队列中排队时间最长的进程
非公平:不考虑线程排队等待的情况,直接尝试获取锁,获取不到再排到队尾等待
因为公平锁需要在多核的情况下维护一个锁线程等待队列,基于该队列进行锁的分配,因此效率比非公平锁低很多
Java中的synchronized是非公平锁,ReentrantLock默认的lock方法采用的是非公平锁。
ReadWriteLock
读写锁分为读锁和写锁两种,多个读锁不互斥,读锁与写锁互斥。在读的地方使用读锁,在写的地方使用写锁,在没有写锁的情况下,读是无阻塞的
ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();
Lock readLock = readLock.readLock(); // 读
Lock writeLock = readLock.writeLock(); // 写
readLock.lock(); writeLock.lock();
readLock.unLock();共享锁和独享锁
独占锁:也叫互斥锁,每次只允许一个线程持有该锁,ReentrantLock为独占锁的实现
共享锁:允许多个线程同时获取该锁,并发访问共享资源。ReentrantReadWriteLock中的读锁为共享锁的实现
重量级锁和轻量级锁
重量级锁是基于操作系统的互斥量(Mutex Lock)而实现的锁,会导致进程在用户态与内核态之间切换,相对开销较大。
synchronized在内部基于监视器锁(Monitor)实现,监视器锁基于底层的操作系统的Mutex Lock实现,因此synchronized属于重量级锁。
JDK1.6,为了减少获取锁和释放锁所带来的性能消耗及提高性能,引入了轻量级锁和偏向锁。
轻量级锁的核心设计是在没有多线程竞争的前提下,减少重量级锁的使用以提高系统性能。
轻量级锁适用于线程交替执行同步代码块的情况(即互斥操作),如果同一时刻有多个线程访问同一个锁,则将会导致轻量级锁膨胀为重量级锁。
偏向锁
偏向锁用于在某个线程获取某个锁之后,消除这个线程锁重入(同一个锁被同一个线程多次获取)的开销,看起来似乎是这个线程得到了该锁的偏向(偏袒)
目的是在同一个线程多次获取某个锁的情况下尽量减少轻量级锁的执行路径
因为轻量级锁的获取及释放需要多次CAS(Compare and Swap)原子操作,而偏向锁只需要在切换ThreadID时执行一次CAS原子操作,因此可以提高锁的运行效率。
在出现多线程竞争锁的情况时,JVM会自动撤销偏向锁,因此偏向锁的撤销操作的耗时必须少于节省下来的CAS原子操作的耗时。
轻量级锁用于提高线程交替执行同步块时的性能
偏向锁则在某个线程交替执行同步块时进一步提高性能。
锁的状态 无锁、偏向锁、轻量级锁和重量级锁
分段锁
是一种思想,用于将数据分段并在每个分段上都单独加锁,把锁进一步细粒度化,以提高并发效率。ConcurrentHashMap在内部就是使用分段锁实现的。
同步锁与死锁
在有多个线程同时被阻塞时,它们之间若相互等待对方释放锁资源,就会出现死锁。为了避免出现死锁,可以为锁操作添加超时时间,在线程持有锁超时后自动释放该锁。
锁优化
- 减少锁持有的时间
- 减少锁粒度
- 锁分离:锁分离思想就是读写锁,操作分离思想可以进一步延伸为只要操作互不影响,就可以进一步拆分,比如LinkedBlockingQueue从头部取出数据,并从尾部加入数据。
- 锁粗化:如果锁分得太细,将会导致系统频繁获取锁和释放锁,反而影响性能的提升。在这种情况下,建议将关联性强的锁操作集中起来处理,以提高系统整体的效率
- 锁消除:消除这些不必要的锁来提高系统的性能。
死锁怎么办
预防:破坏四个必要条件中的一个(互斥、持有等待、不可抢占、循环等待)
避免:资源分配,防止进入不安全的状态,银行家算法
检测:
解除:撤销死锁,回收资源
预防
有序资源分配,一次申请完资源,按照资源编号依次申请
同步异步、阻塞非阻塞
同步异步关注的是消息通信机制
同步:发出调用时,没有得到结果前,该调用就不返回,一旦返回就是得到返回值
异步:调用发出前,调用就直接返回了,没有返回结果,ajax
阻塞非阻塞关注的是程序在等待调用结果(消息、返回值)时的状态
阻塞是调用结果返回前,线程会被挂起,调用线程得到结果才返回
实际问题
https://www.cnblogs.com/lixin-link/p/10998058.html
join详解:https://www.iteye.com/blog/uule-1101994
主线程等待子线程结束
// 1. while
thread.isAlive() == true;
Thread.sleep(10);
// 2. join,main调用线程B的join,main将阻塞到B结束(main要获取到B对象的锁,wait意味着拿到锁,直到对象唤醒main)
thread1.start();
thread2.start();
threadX.join();
// 3. wait、notify,都需要在synchronized中调用,否则会抛 InterruptedException 异常
// wait会将获取到的锁都释放
Object lock = new Object();
// thread内
synchronized (lock) {//获取对象锁
lock.notify();//子线程唤醒
}
// main
try {
synchronized (lock) {//这里也是一样
lock.wait();//主线程等待
}
} catch (InterruptedException e) {
e.printStackTrace();
}
// 4. countDownLatch,客人都上车了,师傅才出发 | 放学都走完了才关大门
final CountDownLatch cdl = new CountDownLatch(threadNumber);
cdl.countDown();
try {
cdl.await();//需要捕获异常,当其中线程数为0时这里才会继续运行
}catch (InterruptedException e){
e.printStackTrace();
}
// 5. Future future.get();
ExecutorService executorService = Executors.newFixedThreadPool(1);
Future future = executorService.submit(thread); //子线程启动,将runnable接口对象包装成Callable对象
try {
future.get();//需要捕获两种异常
}catch (InterruptedException e){
e.printStackTrace();
}catch (ExecutionException e){
e.printStackTrace();
}
// 6. BlockingQueue
// ArrayBlockingQueue、LinkedBlockingQueue(默认无限大容量)
// DelayQueue:只有指定延迟时间到了才能获取
//
BlockingQueue queue = new ArrayBlockingQueue(1); //数组型队列,长度为1
try {
queue.put("OK");//在队列中加入数据
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
queue.take();//主线程在队列中获取数据,take()方法会阻塞队列,ps还有不会阻塞的方法
} catch (InterruptedException e) {
e.printStackTrace();
}
// 7. CyclicBarrier,放学后一个寝室的人一起走
CyclicBarrier barrier = new CyclicBarrier(2);//参数为线程数
try {
barrier.await();//阻塞
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
try {
barrier.await(); // 也阻塞,并且当阻塞数量达到指定数目时同时释放
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}JVM
在虚拟机自动内存管理机制下,不需要delete、free内存空间,不容易出现内存泄露和内存溢出问题
内存区域
原文:https://snailclimb.gitee.io/javaguide/#/docs/java/jvm/Java%E5%86%85%E5%AD%98%E5%8C%BA%E5%9F%9F
- 介绍下 Java 内存区域(运行时数据区)
- Java 对象的创建过程(五步,建议能默写出来并且要知道每一步虚拟机做了什么)
- 对象的访问定位的两种方式(句柄和直接指针两种方式)
运行数据区域

1.8后

线程私有的:
- 程序计数器
- 虚拟机栈
- 本地方法栈
线程共享的:
- 堆
- 方法区
- 直接内存(非运行时数据区的一部分)
程序计数器
较小的内存空间,看做当前线程所执行的字节码的行号指示器
字节码解释器工作时通过改变计数器的值,来选取下一跳需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等都需要到程序计数器
线程切换为了能恢复到正确的执行位置,每个线程需要有一个独立的程序计数器,记录当前执行位置,各线程之前计数器互不影响,成为“线程私有内存”
唯一一个不会出现outOfMenoryError的内存区域,生命周期随着线程的创建而创建,结束而死亡
虚拟机栈
线程私有,生命周期和线程相同,方法调用的数据都是通过栈传递
java内存粗略分为堆内存和栈内存(虚拟机栈中局部变量表部分)
java虚拟机栈由多个栈帧组成,每个栈中都有:局部变量表、操作数栈、动态链接、方法出口信息
局部变量表存放
- 编译器可知的数据类型(byte、short、boolean、char、int、float、double、long)
- 对象引用(不同对象本身,可能是一个指向对象起始地址的引用指针,也可能是代表对象的句柄或与对象相关的位置)
java虚拟机栈
- StackOverFlowError:虚拟机栈内存不可以动态扩展,当线程请求栈深度到达最大虚拟机栈最大深度就抛异常
- OutOfMemoryError:内存动态扩展时,无法申请到足够的内存空间
方法调用
java栈保存栈帧,每次函数调用都会有一个对应的栈帧被压入java栈,每次调用结束都会弹出一个
返回方式,栈帧弹出
- return
- 异常
本地方法栈
虚拟机栈为虚拟机执行java方法(字节码)服务
本地方法栈为虚拟机用到的Native方法服务
HotSpot机中虚拟机栈和本地方法栈合二为一
本地方法被执行时,也会创建栈帧,存放本地方法的局部变量表、操作数栈、动态链接、出口信息,与虚拟机栈基本一致
堆
所有线程共享的内存区域,虚拟机启动时创建,用于存放对象示例,几乎所有的对象实例和数组都在这里分配内存,
1.7后,如果方法中的对象应用没有被返回或者没被使用,则对象可以直接在栈上分配内存
java堆是垃圾收集器管理的主要区域,因此被称为GC堆,java堆细分为:新生代、老年代,再细致:Eden、from survivor、To Surivivor空间,进一步划分的目的是更好的回收内存,更快的分配内存
1.8前,堆内存分为:新生代内存、老生代内存、永生代内存

1.8后,永生代移除,取而代之的是元空间(使用直接内存)

大部分情况下,对象首先在Eden区分配,进行一次新生代垃圾回收后,如果对象还存活,则进入s0或者s1,对象年龄增加1
当它的年龄增加到一定程度(默认15岁,通过-XX:maxTenuringThreshold设置),就会晋升到老年代中
堆错误
- OutOfMemoryError:GC Overhead Limit Exceeded:当JVM花太多时间执行垃圾回收,并且只能回收少量的堆空间时,就会发生此类错误
- java.lang.OutOfMemory:java heap space: 创建新对象时,堆空间不足,与本机物理内存无关,与配置的内存大小有关
方法区
元空间
与Java堆一样,各个线程共享的内存区域,存放被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
JAVA虚拟机规范把方法区描述为堆的一个逻辑部分,但是别名为Non-Heap,与java堆区分开
方法区和永生代关系
方法区(接口),永生类(类),HotSpot永生代就是方法区中的实现方式(其他虚拟机没有永生代说法)
常用参数
1.8前
-XX:PermSize=N # 初始
-XX:MaxPermSize=N # 最大,超过则OutOfMemoryError: PermGen1.8后,如果不指定大小,随着类的创建,虚拟机可能会消耗掉所有系统内存
-XX:MetaspaceSize=N
-XX:MaxMetaspaceSize=N运行时常量池
方法区的一部分,受到方法区内存限制,class文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池表(存放编译期生成的各种字面量和符号引用)
字面量:String类型的字符串常量
1.8,字符串常量池还在堆,运行时常量池还在方法区,方法区的实现变成了元空间
直接内存
不是虚拟机运行时数据区的一部分,也不是虚拟机规范定义的内存区域,可能OutOfMemoryError
1.4后加入NIO(New Input/Output)类引入了基于通道、缓存区的IO方式可以直接使用Native函数库直接分配对外内存,通过一个存储在Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作,避免在Java堆和Native堆之间来回复制数据
受到主机总内存大小以及存储器寻址空间限制
HotSpot虚拟机对象

对象创建
类加载检查:查看类是否加载过,没有就执行类加载过程
分配内存:类加载后知道需要多少内存,在java堆中划分一块内存,有指针碰撞(没有内存碎片)和空闲列表(哪个地方是够空间的)
初始化零值:将内存空间初始化零值,java代码不赋初值就能使用
设置头对象:记录对象的信息(是哪个类的实例、GC分代年龄、哈希码)存放到对象头
init方法:按我们的意愿初始化类
Step1:类加载检查
new时,检查指令参数能够在常量池中定位到这个类的符号引用,检查这个符号引用代表的类是否已被加载过、解析、初始化过,如果没有则先执行相应的类加载过程
Step2:分配内存
为新生对象分配内存,对象所需的内存大小在类加载完后确定,把一块确定大小的内存从java堆中划分出来
分配方式有:指针碰撞和空闲列表,由JAVA堆是否规整决定,是否规整由采用的垃圾收集器是否带有压缩整理功能决定

并发问题
虚拟机必须保证,创建对象的线程安全
TLAB:为每个线程预先在Eden区分配一块内存
CAS + 失败重试:CAS乐观锁的实现方式,每次不加锁,完成操作时因为冲突失败就重试,直到成功
JVM给线程中的对象分配内存时,首先在TLAB分配,当对象中大于TLAB剩余内存或TLAB内存用尽时,再采用CAS分配
Step3:初始化零值
分配内存后,虚拟机需要将分配到的内存空间都初始化为零值,这一步保证了对象的实例字段在Java代码中不赋初始值就直接使用,程序能够访问这些字段的数据类型对应的零值
Step4:设置头对象
初始化零值后,对对象进行必要设置,
例如这个对象是哪个类的实例、如何找到类的元数据信息、对象的哈希码,对象的GC分代年龄等信息,这些信息存放在对象头中,
根据虚拟机的运行状态,是否启用偏向锁,对象头会有不同的设置
Step5:执行init方法
虚拟机看来,一个对象已经产生,但是对于JAVA,对象创建才刚开始,init方法没有执行,所有字段都为零,所以执行new指令后会执行init方法,把对象按我们的意愿初始化。
对象的内存布局
hotspot中,对象在内存中的布局分为3个区域:对象头、实例数据、对齐填充
对象头:
- 第一部分存储自身对象运行时的数据(哈希码、GC分代年龄、锁状态标志等等)
- 另一部分是类型指针,指向它的类元数据的指针,虚拟机通过这个指针确定改对象是哪个类的实例
实例数据部分是对象真正存储的有效信息
对齐填充不是必然存在的,仅仅起占位作用,hotspot要求对象大小必须是8字节的整数倍
对象的访问定位
通过栈上的reference数据来操作堆上的具体对象,对象的访问方式由虚拟机实现,主要有:使用句柄、直接指针
句柄:java堆会划分出内存作为句柄池,reference中存储的就是对象的句柄地址,而句柄包括了对象实例数据和类型数据各自的具体地址信息

直接指针:java堆对象考虑如何放置访问数据的相关信息,而reference中存储的直接就是对象的地址

句柄好处是reference中存储的是稳定的句柄地址,在对象被移动时只改变句柄中的实例数据指针,reference本身不需要修改
直接指针访问,速度快,节省了一次指针定位的时间开销
补充
String和常量池
只要使用 new 方法,便需要创建新的对象
String str = "abcd"; // 先检查常量池有没有"abcd",没有就创建一个,有就直接指向String类型的常量池
- 直接双引号声明的String对象直接存储在常量池中
- 不是双引号声明的String对象,可以用String.intern()方法,是一个native方法
- 如果运行时常量池已经包含一个等于次String对象内容的字符串,则返回常量池中该字符串的引用
- 如果没有,1.7前是常量池中创建与String相同的字符串,并返回常量池创建的字符串的应用
- 1.8在常量池中记录此字符串的引用,返回该引用
字符串拼接:
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing";//常量池中的对象
String str4 = str1 + str2; //在堆上创建的新的对象
String str5 = "string";//常量池中的对象
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false
避免字符串拼接,这样会重新创建对象
String s1 = new String(“abc”)创建对象
将创建1或2个对象
如果常量池中已经有abc,则在堆空间创建一个字符串常量abc
如果池中没有字符串常量abc,那么先在池中创建,再到堆中创建
基本类型包装类和常量池
Byte,Short,Integer,Long,Character,Boolean,
前面4种包装类创建数值[-128, 127]相应的缓存数据,
Character创建了数字在[0, 127]范围的缓存,
Boolean直接返回True or False
超过范围将创建新的对象
- Integer i1=40;Java 在编译的时候会直接将代码封装成 Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。
- Integer i1 = new Integer(40);这种情况下会创建新的对象。
- 相加,会对Integer对象拆箱
RabbitMQ
erLang语言实现的AMQP的消息中间件,在分布式系统中存储转发消息
特点:
可靠:通过机制保障消息可靠(发出、接收,接收到回复),持久化、==传输确认和发布确认==
灵活的路由:消息进入队列前,通过交换机来路由信息
扩展性:可以组成集群,动态扩展节点
高可用:队列在集群中的机器上设置镜像
多种协议:AMQP、STOMP、MQTT等多种消息中间件协议
多语言客户端:java、python、php、javascript
易用的用户界面
多插件支持
缺点:
降低系统稳定性,消息队列挂了,系统不可用
增加复杂性,一致性问题,消息不可重复消费,可靠性传输
面试
消息幂等性
正常情况下,消费者消费信息后,会发送确认信息给消息队列,消息队列知道消息被消费了,再将消息从消息队列删除
但是网络传输故障,确认信息没有传送到消息队列,再次将消息发送到其他消费者
解决:
接受message,获取消息tag和msgId,判断redis是否存在msgId,开启手动确认
可靠传输
消息丢失、劫持
生产者丢失:transaction和confirm确保生产者不丢消息
transaction:发送消息前开启事务(channel.txSelect()),发送消息常出现异常,事务回滚(channel.txRollback() ),成功则提交事务(channel.txCommt())
缺点:吞吐量下降
confirm:所有发布的消息都有唯一的ID(1开始),消息投递到队列后,rabbitMq发送ack给生产者,确保消息正确,没能处理则发送Nack,进行重试操作
工具
Maven
生命周期
| 阶段 | 处理 | 描述 |
|---|---|---|
| validate | 验证项目 | 验证项目正确,信息可用 |
| compile | 执行编译 | 源代码编译 |
| Test | 测试 | 单元测试框架测试 |
| package | 打包 | 创建 jar / war |
| verify | 检查 | 对集成测试的结果进行检查 |
| install | 安装 | 安装打包的项目到本地仓库,供其他项目使用 |
| deploy | 部署 | 拷贝最终的工程包到远程仓库,分享给其他开发人员 |
编译原理
有限状态机(Finite State Machine,FSM)是一种数学模型,它包括有限个状态以及在这些状态之间的转移和动作等行为。它可以用来进行对象行为建模,描述对象在其生命周期内所经历的状态序列,以及如何响应来自外界的各种事件。
有限状态机通常包括以下几个部分:
- 状态(State):表示系统的当前状态。
- 事件(Event):表示触发状态转换的条件。
- 转换(Transition):表示从一个状态到另一个状态的过渡。
- 动作(Action):表示在状态转换过程中执行的操作。