快速入门
简介
from:https://www.cnblogs.com/h--d/p/15591075.html
官方文档:https://docs.spring.io/spring-batch/docs/current/reference/html/index.html
轻量级、完善高效的批处理框架
提供可重用组件,日志追踪、事务、任务作业统计、任务重启、跳过、重复资源管理
提供高级功能和特性:分区、远程功能,处理对于大数据量、高性能批处理任务
需要和调度框架(Quartz等)合作完成批处理任务,它只关注任务相关的问题,如:事务、并发、监控、执行
主要功能:
- 事务管理
- 基于块的处理
- 声明式的输入输出
- 启动、停止、再启动
- 重试、跳过
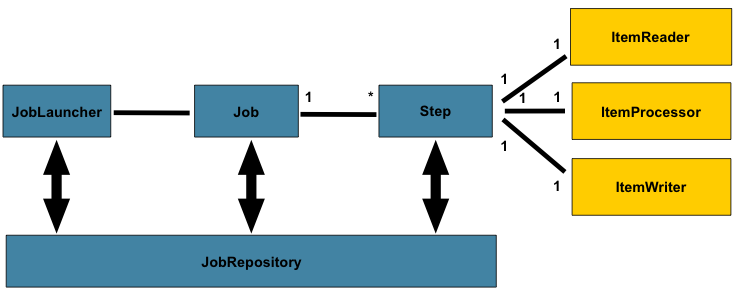
一个jobLauncher集合job和jobParameter,运行一个job可以定时运行多次,每次产生jobInstance(根据jobParameter区分),运行时产生JobExcution记录成功失败,Job包含多个Step,Step每次实际运行都产生StepExecution,step中大体操作为Item Reader、Processor、Item Write,读写可以操作数据库或文件
包含角色
- JobLauncher(任务启动器),用来启动任务,程序的入口
- Job(具体的任务)
- Step(一个任务中包含多个step步骤)
- JobRepository(数据存放),数据库接口,任务执行时记录任务状态
入门程序
依赖
springboot、springBatch、mysql
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.test</groupId>
<artifactId>test-springboot-batch</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>数据库配置
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://127.0.0.1:3306/test_springbatch?allowPublicKeyRetrieval=true&useSSL=true
driver-class-name: com.mysql.cj.jdbc.Driver
# 初始化数据库,文件在依赖jar包中
schema: classpath:org/springframework/batch/core/schema-mysql.sql
initialization-mode: always
启动类
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}Job/Step
简单
@Configuration
// 启用批处理功能
@EnableBatchProcessing
public class JobConfiguration {
// 注入创建任务的对象
@Autowired
private JobBuilderFactory jobBuilderFactory;
// 注入创建步骤的对象
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job helloworldJob() {
return jobBuilderFactory.get("helloworldJob")
.start(step1())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
System.out.println(Thread.currentThread().getName() + "------" + "hello world");
// 返回执行完成状态
return RepeatStatus.FINISHED;
}
}).build();
}
}运行
运行启动类后,自动执行了任务

参考示例
稍微完整
@EnableBatchProcessing
@Configuration
public class JdbcBatchItemWriterJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(
job,
new JobParametersBuilder()
.addDate("date", new Date()).toJobParameters()
);
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("jdbc-batch-item-writer-step")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, JdbcBatchItemWriter<People> writer) {
AtomicLong atomicLong = new AtomicLong();
return stepBuilderFactory.get("jdbc-batch-item-writer-step")
.<People, People>chunk(3)
.reader(() -> atomicLong.get() > 20 ? null : new People(null, "name : " + atomicLong.getAndIncrement()))
.processor((Function<People, People>) item -> {
System.out.println("process : " + item);
return item;
})
.writer(writer)
.build();
}
@Bean
public JdbcBatchItemWriter<People> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<People>()
.dataSource(dataSource)
.sql("insert into people(id,name) values(null,?)")
.itemPreparedStatementSetter(((item, ps) -> ps.setString(1, item.getName())))
.assertUpdates(false)
.build();
}
}核心API
Job
Job是一个封装整个批处理过程的一个概念,代码当中它只是一个最上层的接口
public interface Job {
String getName();
boolean isRestartable();
void execute(JobExecution execution);
JobParametersIncrementer getJobParametersIncrementer();
JobParametersValidator getJobParametersValidator();
}实现类:simplejob,flowjob
job是运行的基本单位,由step组成,可以按照逻辑顺序组合step,给所有step设置相同属性的方法,如事件监听,跳过策略
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.end()
.build();
}JobInstance
public interface JobInstance {
public long getInstanceId();
public String getJobName();
}job在运行时,作业执行过程当中的概念
JobParameters
job每次运行都有一个jobInstance,通过jobParameters标识,包含一组用于批处理作业的参数(如运行时间)
JobInstance = JobParameters + Job
JobExecution
job的一次执行有可能成功也可能失败,只有成功完成时,jobInstance才完成
相同的JobParameter参数相同,第一次失败,第二次还使用时,JobInstance还是只有一个,但是会新建一个JobExecution
public interface JobExecution {
public long getExecutionId();
public String getJobName();
/** public enum BatchStatus {STARTING, STARTED, STOPPING, STOPPED, FAILED, COMPLETED, ABANDONED } */
public BatchStatus getBatchStatus();
public Date getStartTime();
public Date getEndTime();
public String getExitStatus();
public Date getCreateTime();
public Date getLastUpdatedTime();
public Properties getJobParameters();
}spring batch会将他们持久到数据库当中
在使用Spring batch的过程当中spring batch会自动创建一些表用于存储一些job相关的信息
用于存储JobExecution的表为batch_job_execution
step
Step包含定义和控制实际批处理所需的所有信息,由开发指定
如过一个step的功能是将文件中的数据加载到数据库,基于SpringBatch几乎不需要写代码

StepExecution
stepExecution表示执行一次step
每次实际运行一个step才会创建一个新的StepExecution
每个StepExecution都包含对其相应步骤的引用以及JobExecution和事务相关的数据,例如提交和回滚计数以及开始和结束时间。
每个步骤执行都包含一个ExecutionContext,其中包含开发人员需要在批处理运行中保留的任何数据,例如重新启动需要的统计信息和状态信息
ExecutionContext
ExecutionContext即每一个StepExecution 的执行环境。它包含一系列的键值对
获取
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();JobRepository
持久化的类,给Job、Step、JobLaucher实现提供CRUD
首次启动Job时,将从repository中获取JobExecution
并且在执行批处理的过程中,StepExecution和JobExecution将被存储到repository当中
@EnableBatchProcessing注解可以为JobRepository提供自动配置
JobLauncher
用于启动指定了JobParameter的Job
public interface JobLauncher {
/**
* 实现的功能是根据传入的job以及jobparamaters
* 从JobRepository获取一个JobExecution并执行Job
*/
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}Item Reader
itemReader是一个读数据的抽象,为Step提供数据输入
如果itemReader已经读完所有数据,会返回null告诉后续操作数据已经读完
实现类:JDBCPagingItemReader、JDBCCursorItemReader等
可以读数据库、文件、数据流等
| Reader | 目的 |
|---|---|
| FlatFIleItemReader | 从平面文件中读取数据。 |
| StaxEventItemReader | 从 XML 文件中读取数据。 |
| StoredProcedureItemReader | 从数据库的存储过程中读取数据。 |
| JDBCPagingItemReader | 从关系数据库数据库中读取数据。 |
| MongoItemReader | 从 MongoDB 读取数据。 |
| Neo4jItemReader | 从 Neo4j ItemReader 读取数据。 |
JdbcPagingItemReader
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
/**
* JdbcPagingItemReader必须指定一个PagingQueryProvider,负责提供SQL查询语句来按分页返回数据。
*/
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}JdbcCursorItemReader
private JdbcCursorItemReader<Map<String, Object>> buildItemReader(final DataSource dataSource, String tableName,
String tenant) {
JdbcCursorItemReader<Map<String, Object>> itemReader = new JdbcCursorItemReader<>();
itemReader.setDataSource(dataSource);
itemReader.setSql("sql here");
itemReader.setRowMapper(new RowMapper());
return itemReader;
}Item Writer
写数据的抽象,为每个Step提供数据写功能
一次可以写一条,也可以写一个chunk
| Writer | 目的 |
|---|---|
| FlatFIleItemWriter | 将数据写入平面文件。 |
| StaxEventItemWriter | 将数据写入 XML 文件。 |
| StoredProcedureItemWriter | 将数据写入数据库的存储过程。 |
| JDBCPagingItemWriter | 将数据写入关系数据库。 |
| MongoItemWriter | 将数据写入 MongoDB。 |
| Neo4jItemWriter | 将数据写入 Neo4j。 |
@EnableBatchProcessing
@Configuration
public class JdbcBatchItemWriterJobConf {
@Bean
public String runJob(JobLauncher jobLauncher, Job job) throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
jobLauncher.run(job, new JobParametersBuilder()
.addDate("date", new Date()).toJobParameters());
return "";
}
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("jdbc-batch-item-writer-step")
.start(step)
.build();
}
@Bean
public Step step(StepBuilderFactory stepBuilderFactory, JdbcBatchItemWriter<People> writer) {
AtomicLong atomicLong = new AtomicLong();
return stepBuilderFactory.get("jdbc-batch-item-writer-step")
.<People, People>chunk(3)
.reader(() -> atomicLong.get() > 20 ? null : new People(null, "name : " + atomicLong.getAndIncrement()))
.processor((Function<People, People>) item -> {
System.out.println("process : " + item);
return item;
})
.writer(writer)
.build();
}
@Bean
public JdbcBatchItemWriter<People> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<People>()
.dataSource(dataSource)
.sql("insert into people(id,name) values(null,?)")
.itemPreparedStatementSetter(((item, ps) -> ps.setString(1, item.getName())))
.assertUpdates(false)
.build();
}
}Item Processor
在ItemReader读一条数据后,itemWriter未写入这条记录前
借助ItemProcessor处理业务逻辑,对数据进行操作,如果一条数据不应该被写入,可以返回null
Chunk处理流程

一次batch的任务可能多次数据读写,一条条处理并提交数据库效率不高
使用chunk,设定一个chunk size,spring batch一条条处理数据,但不提交数据库,只有数据量达到chunk size才一起commit

chunk size被设为了10,当ItemReader读的数据数量达到10的时候,这一批次的数据就一起被传到itemWriter,同时transaction被提交
skip策略和失败处理

skipLimit(),skip(),noSkip()
skipLimit设定step可以跳过的异常数量,默认为0,如果超过其,step就会失败
skip可以指定跳过的的异常,有些异常是可以忽略的
noSkip,上述例子中,跳过所有不是FileNotFoundException的Exception,当出现FileNotFoundException时,step会直接fail
操作指南
批处理体系结构通常会影响体系结构
尽可能简化并避免在单批应用程序中构建复杂的逻辑结构
保持数据的处理和存储在物理上靠得很近(换句话说,将数据保存在处理过程中)。
最大限度地减少系统资源的使用
查看应用程序I / O(分析SQL语句)以确保避免不必要的物理I / O,避免以下
- 当数据可以被读取一次并缓存或保存在工作存储中时,读取每个事务的数据。【?】
- 重新读取先前在同一事务中读取数据的事务的数据。
- 导致不必要的表或索引扫描。
- 未在SQL语句的WHERE子句中指定键值。
在批处理运行中不要做两次一样的事情。例如,如果需要数据汇总以用于报告目的,则应该在最初处理数据时递增存储的总计
在批处理应用程序开始时分配足够的内存,以避免在此过程中进行耗时的重新分配。
总是假设数据完整性最差。插入适当的检查和记录验证以维护数据完整性。
尽可能实施校验和以进行内部验证。例如,对于一个文件里的数据应该有一个数据条数纪录,告诉文件中的记录总数以及关键字段的汇总。
在具有真实数据量的类似生产环境中尽早计划和执行压力测试。
在大批量系统中,数据备份可能具有挑战性,特别是如果系统以24-7在线的情况运行。文件备份很重要,如果系统依赖于文件,则还应定期进行测试文件备份。
默认不启动
使用spring batch的job时,项目在启动时就会默认去跑我们定义好的批处理job
spring.batch.job.enabled=false读时内存不够
红字的信息为:Resource exhaustion event:the JVM was unable to allocate memory from the heap.
造成这个错误的原因是: 这个项目里的batch job的reader是一次性拿回了数据库里的所有数据,并没有进行分页,当这个数据量太大时,就会导致内存不够用。解决的办法有两个:
- 调整reader读数据逻辑,按分页读取,但实现上会麻烦一些,且运行效率会下降
- 增大service内存